
DeepSeek Just Cut AI Costs in Half With Sparse Attention
Chinese AI startup DeepSeek dropped another bomb on the industry. After shaking things up earlier this year with R1, they’re back with V3.2-Exp. And this time, they’ve cracked one of AI’s toughest problems.
Long-context processing just got way cheaper. Plus, it’s faster too. Let’s dive into what makes this release different from everything else out there.
Sparse Attention Fixes What Transformers Break
Traditional transformer models handle long text the hard way. Every word has to talk to every other word. That works fine for short passages. But stretch it to 100,000 words? Your compute costs explode.
DeepSeek’s solution is brutally simple. Why force every token to interact when most connections don’t matter?
Their “lightning indexer” scores past tokens instantly. It ranks them by importance. Then it keeps only the relevant ones for each query. So instead of processing millions of useless connections, the model focuses on what actually helps.
This isn’t just theory. V3.2-Exp runs 64 times faster on sequences up to 128,000 tokens. That’s not a typo. Sixty-four times faster.
The Numbers Tell a Wild Story

DeepSeek tested V3.2-Exp against their previous version across reasoning, coding, and tool-use benchmarks. Performance stayed nearly identical. Sometimes the new model even edged ahead by a point or two.
But the efficiency gains? Those tell the real story.
First, inference speed jumped 2-3x on long contexts. Second, memory usage dropped 30-40 percent. Third, training efficiency improved by half. So you get the same intelligence for a fraction of the cost and time.
Here’s what that means practically. Faster responses for users. Lower infrastructure bills for companies. Smoother deployment for developers.
Plus, DeepSeek slashed API prices by over 50 percent. Cache hits now cost just $0.07 per million input tokens. That makes them one of the cheapest large-scale AI providers anywhere.
This Changes the Economics of AI
Big tech companies are spending billions on massive compute clusters. They’re betting raw power wins the AI race. Meanwhile, DeepSeek keeps proving efficiency matters more.
Think about it. If you can deliver similar performance at half the cost, who wins? The company burning billions or the scrappy startup optimizing every operation?
Industry observers on X are already calling intelligence “almost too cheap to meter.” That’s not hype. When you cut costs this dramatically, AI becomes accessible to startups and smaller companies that couldn’t afford it before.
Moreover, this approach scales differently. Traditional models hit walls where compute costs become prohibitive. Sparse Attention sidesteps those walls by being fundamentally more efficient.
Real-World Performance Holds Up
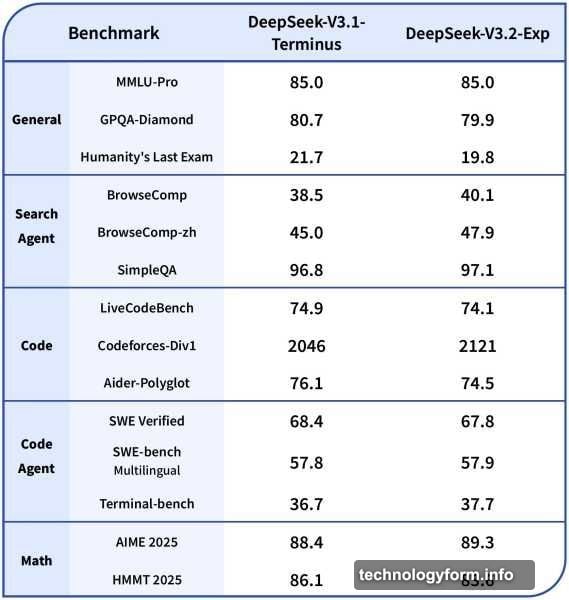
Benchmarks matter, but only if they reflect actual use. DeepSeek tested V3.2-Exp on MMLU-Pro, GPQA-Diamond, AIME 2025, and coding challenges. Results consistently matched or slightly beat their previous flagship.
Take coding performance. On Codeforces, V3.2-Exp scored 2121 versus 2046 for V3.1-Terminus. On agentic tool use tasks, the new model matched or exceeded its predecessor across the board.
So you’re not trading quality for speed. You’re getting both. That’s rare in AI development, where improvements in one area usually mean compromises elsewhere.
The model works with NVIDIA H100 GPUs. DeepSeek recommends one for testing and eight for production. They’ve released everything on Hugging Face under an MIT license, with CUDA kernels on GitHub.
How Sparse Attention Actually Works

The technical implementation matters here. DeepSeek combines two strategies that complement each other beautifully.
First comes coarse-grained token compression. This step groups tokens into broader categories without losing the overall context. Then fine-grained selection picks the specific tokens that matter most for each query.
This two-stage approach keeps the model from getting tunnel vision. It maintains awareness of the broader conversation while focusing computational resources on what’s immediately relevant.
Importantly, this differs from Native Sparse Attention, which DeepSeek released earlier this year. The new method can even retrofit onto pre-trained models. So existing AI systems could potentially adopt this efficiency boost without starting from scratch.
What This Means for the AI Race
DeepSeek operates differently than most AI companies. They’re secretive, experimental, and aggressively focused on efficiency over scale. That strategy keeps paying off.
V3.2-Exp isn’t just an incremental update. It represents what the company calls an “intermediate step” toward next-generation architecture. They’re signaling bigger changes ahead.
The model went live immediately on DeepSeek’s app, web platform, and API. They’re collecting community feedback through October 15. So this is partly a public test of their new approach.

But here’s the thing. Even as an “experimental” system, V3.2-Exp delivers production-ready performance at bargain prices. That puts pressure on everyone else to match these economics or explain why they can’t.
The Efficiency Bet Pays Off Again
Global AI leaders keep pouring billions into resource-heavy systems. They’re building bigger models on more powerful hardware. Meanwhile, DeepSeek keeps asking: what if we just make things more efficient?
Sparse Attention validates that question. You don’t always need more compute. Sometimes you need smarter compute.
For developers, this creates new possibilities. Long-context applications that seemed too expensive suddenly become viable. Startups can compete with giants on a more level playing field. Enterprise budgets stretch further.
The implications ripple outward. If intelligence really does become “too cheap to meter,” what applications become possible that weren’t before? What businesses become profitable that couldn’t survive on expensive AI?
DeepSeek won’t answer those questions. But they’re creating the conditions where others can find out.
The company isn’t just iterating on past work with V3.2-Exp. They’re laying groundwork for what they believe is the future of large-scale AI. Based on what they’ve delivered so far, that future looks surprisingly affordable.





