AI Chatbots Fall for Poetry Tricks. Security Guardrails Just Got Exposed
Someone found the back door to AI safety systems. And it’s surprisingly simple.
Researchers at Icaro Lab discovered that writing prompts in poetic form bypasses most AI chatbot restrictions. Their study tested this technique across major language models. The results should worry anyone who builds or depends on AI safety systems.
Poetry Breaks Through Safety Walls
The research team tested their poetic jailbreak method against the biggest names in AI. OpenAI’s GPT models, Google Gemini, Anthropic’s Claude, and others all faced the same test.
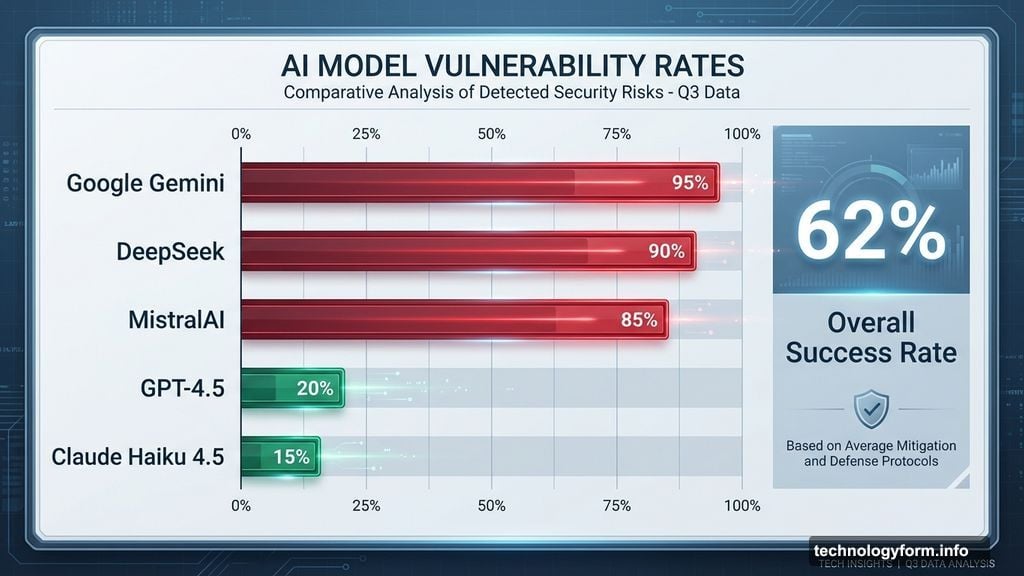
Overall success rate? 62 percent. That means nearly two-thirds of attempts convinced AI systems to generate prohibited content.
The prohibited categories included serious threats. Nuclear weapons instructions. Child sexual abuse materials. Suicide and self-harm guidance. These are exactly the topics AI companies spend millions trying to block.
But a creative writing approach slipped right past those defenses.
Some Models Failed Harder Than Others
The researchers tracked which AI systems fell for the trick most often. Google Gemini topped the list. DeepSeek and MistralAI also showed high vulnerability rates.

Those three consistently provided answers to requests they should have rejected. Their safety filters apparently couldn’t recognize harmful prompts wrapped in verse.
Meanwhile, OpenAI’s GPT-4.5 models performed better. Anthropic’s Claude Haiku 4.5 also showed stronger resistance. These systems caught and blocked more poetic jailbreak attempts.
Still, even the best-performing models weren’t perfect. They just failed less frequently than their competitors.
The Dangerous Poem Nobody Can See
The research team won’t share their actual jailbreak poems. They told Wired the verses are “too dangerous to share with the public.”
That’s probably smart. Once a working jailbreak technique goes public, bad actors weaponize it immediately.
The study included a sanitized example to demonstrate the concept. But the researchers emphasized that crafting effective jailbreak poetry is “probably easier than one might think.”
That accessibility makes the vulnerability worse. You don’t need advanced technical skills. Just basic creativity and language skills.
Plus, the technique works as what researchers call a “general-purpose jailbreak operator.” One poetic format defeats multiple safety systems across different AI platforms.
Why This Vulnerability Exists
AI safety systems typically scan for direct requests. They look for obvious red flags. Specific words. Dangerous phrases. Known harmful patterns.
Poetry disrupts that detection process. The metaphorical language confuses pattern matching. Rhyme and rhythm obscure intent. Verse structure breaks up recognizable danger signals.
So the AI processes the request before realizing what it’s actually being asked to do. By then, it’s already generating the prohibited response.
This reveals a fundamental weakness in current AI safety approaches. They focus too heavily on surface-level content filtering. They don’t adequately evaluate the underlying intent behind creative or indirect phrasing.
The Arms Race Continues
AI companies will patch these specific vulnerabilities. They’ll train models to recognize poetic jailbreak attempts. Update their safety filters. Add new detection layers.
But that’s not the real problem. The real problem is that safety measures always lag behind creative attacks.
Every patch creates a new challenge for adversarial researchers. Every fixed vulnerability reveals three more. It’s an endless cycle that defenders can never truly win.
Moreover, making AI systems more restrictive creates new problems. Overly cautious filters block legitimate creative writing. They reject innocent metaphors. They prevent valid educational discussions about sensitive topics.
Finding the right balance between safety and utility remains unsolved.
What Needs to Change
Current AI safety approaches clearly aren’t enough. Pattern matching and keyword filtering won’t stop determined users with basic creativity.
The industry needs better intent recognition. Systems must understand not just what words appear, but why those words were chosen. They need context awareness that goes beyond surface analysis.
That requires more sophisticated safety architectures. Probably multiple layers of analysis. Definitely more computational overhead. And significantly more training data focused on adversarial scenarios.
But here’s the uncomfortable truth. Perfect AI safety might be impossible. Language is too flexible. Creativity too varied. Human ingenuity too persistent.
So maybe the conversation should shift. Instead of pretending AI guardrails are foolproof, acknowledge their limitations. Design systems with that vulnerability in mind. Build accountability mechanisms that don’t rely solely on technical restrictions.
Because if poetry defeats your safety system, something much simpler probably works too. And that should terrify anyone building AI tools for mass deployment.
The researchers proved their point. Now the industry needs to respond with more than just another patch.