
The New York Times Just Sued Perplexity for Copyright Theft
AI search engines are scraping news content without permission. Now publishers are fighting back hard.
The New York Times filed a federal lawsuit against Perplexity on Friday. The complaint accuses the AI startup of illegally copying Times stories, videos, and podcasts to power its search engine. Plus, this isn’t an isolated incident. The Chicago Tribune filed a nearly identical lawsuit just one day earlier.
So the battle over AI training data just escalated from industry tension to courtroom warfare.
Perplexity Built Its Search Engine on Stolen Content
The lawsuit claims Perplexity scraped Times content without authorization. Then the startup used that material to generate answers for user queries.
Here’s the problem. Perplexity’s responses often look “identical or substantially similar” to original Times articles, according to the complaint. That’s not summarizing or referencing. That’s copying with extra steps.
The Times isn’t alone in making these claims. The Chicago Tribune filed suit on Thursday with the same accusations. Both publishers argue Perplexity built its business by taking their content without paying for it or asking permission.
“While we believe in the ethical and responsible use and development of AI, we firmly object to Perplexity’s unlicensed use of our content,” said Graham James, a Times spokesperson. The message is clear: license our content properly or face legal consequences.
AI Companies Keep Dismissing Copyright Claims
Perplexity’s response? Basically, “everyone sues new tech companies.”
Jesse Dwyer, Perplexity’s head of communication, said publishers have been filing lawsuits against new technology “for a hundred years, starting with radio, TV, the internet, social media and now AI.” His conclusion: “Fortunately it’s never worked, or we’d all be talking about this by telegraph.”
That’s a bold stance. But it ignores key differences between AI scraping and previous technological shifts.
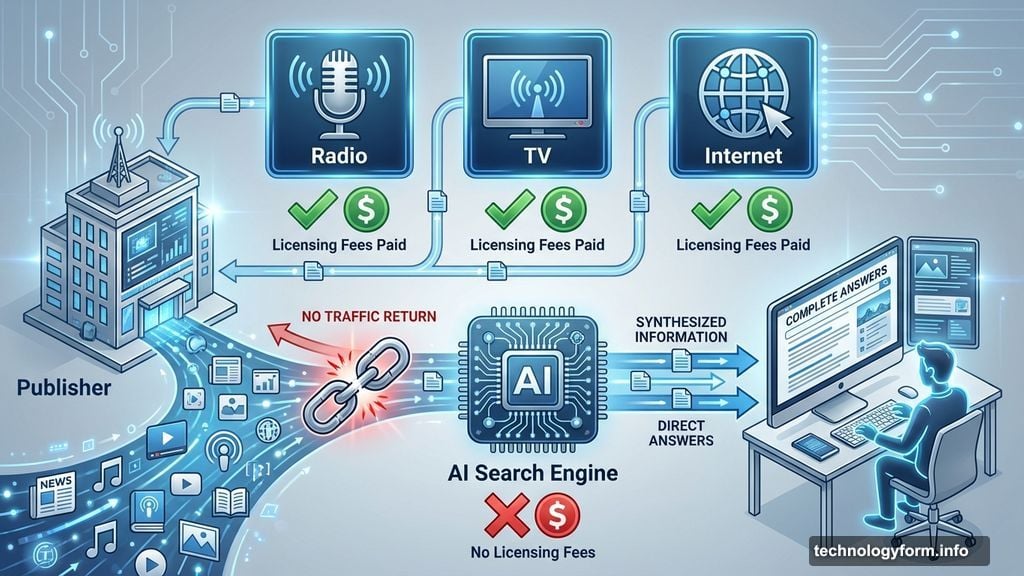
Radio and TV broadcasters paid licensing fees for content. Internet search engines directed traffic back to publishers through links. Social media platforms created new distribution channels that drove audience growth.
However, AI search engines like Perplexity give users complete answers. So readers never visit the original publisher’s website. No traffic means no ad revenue, no subscriptions, and no business model for journalism.
Publishers Are Done Negotiating
The Times already has another major lawsuit pending. In 2023, the newspaper sued Microsoft and OpenAI for using Times content to train ChatGPT without permission. That case is still moving through federal court in the Southern District of New York.
Meanwhile, other AI companies are choosing different paths. Anthropic agreed to pay $1.5 billion in September to settle a class action lawsuit with authors. That settlement represents the largest publicly reported copyright recovery in AI training disputes.
The contrast is striking. Some AI companies settle and establish licensing agreements. Others, like Perplexity, dismiss copyright concerns entirely and dare publishers to prove their case in court.
Why This Lawsuit Matters More Than Previous Cases
Perplexity raised over $1.5 billion from investors including IVP, New Enterprise Associates, and Nvidia. The company has significant resources and backing from major tech players.
But that funding creates higher stakes. If Perplexity loses this lawsuit, the damages could be substantial. Courts might order the company to pay for every piece of content it scraped. They could also impose penalties for willful copyright infringement.
Moreover, a ruling against Perplexity would set precedent for other AI companies. Every startup building on scraped news content would face similar legal exposure. That could force the industry toward licensing deals rather than taking content without asking.
The Real Problem Nobody’s Solving
AI search engines fundamentally break the publishing business model. Traditional search engines sent users to websites. So publishers could monetize through ads and subscriptions.
Now AI tools give complete answers without sending traffic. Publishers create the content. AI companies monetize it. That’s not innovation. That’s value extraction.
Perplexity argues this fight mirrors past technology disputes. But those cases involved distribution channels that ultimately helped publishers reach audiences. AI search eliminates the need for audiences to visit publishers at all.
The Times and Tribune aren’t fighting against technological progress. They’re fighting for basic compensation when companies profit from their work. That’s not about resisting change. That’s about protecting the financial foundation that makes journalism possible.





