AI Bots Now Dominate Web Traffic. Here’s the Arms Race Brewing
AI bots are taking over the Internet. And most websites have no idea how to fight back.
A new report reveals that automated AI scrapers now account for a massive chunk of web traffic. Plus, these bots are getting smarter at evading detection. What started as a copyright battle has evolved into something bigger—a fundamental shift in how the web operates.
The stakes? Control over who accesses online content and whether humans or machines will dominate Internet traffic in the years ahead.
AI Scraping Traffic Jumped 400 Percent
TollBit, a company tracking web-scraping activity, released findings that show explosive growth. In Q4 2025, one out of every 31 website visits came from AI scraping bots. That’s up from just one in 200 visits during Q1.
Even more concerning, over 13 percent of bot requests now ignore robots.txt files. These files tell bots which pages to avoid. But many AI scrapers simply bypass them.
That 13 percent represents a 400 percent increase from earlier in 2025. So bots aren’t just proliferating—they’re getting bolder about breaking the rules.
Akamai, a major Internet infrastructure firm, confirmed the trend. Their data shows training-related bot traffic climbing steadily since July 2024. Meanwhile, bots fetching real-time web content for AI agents are also surging.
“AI is changing the web as we know it,” says Robert Blumofe, Akamai’s chief technology officer. The question is whether websites can keep up.

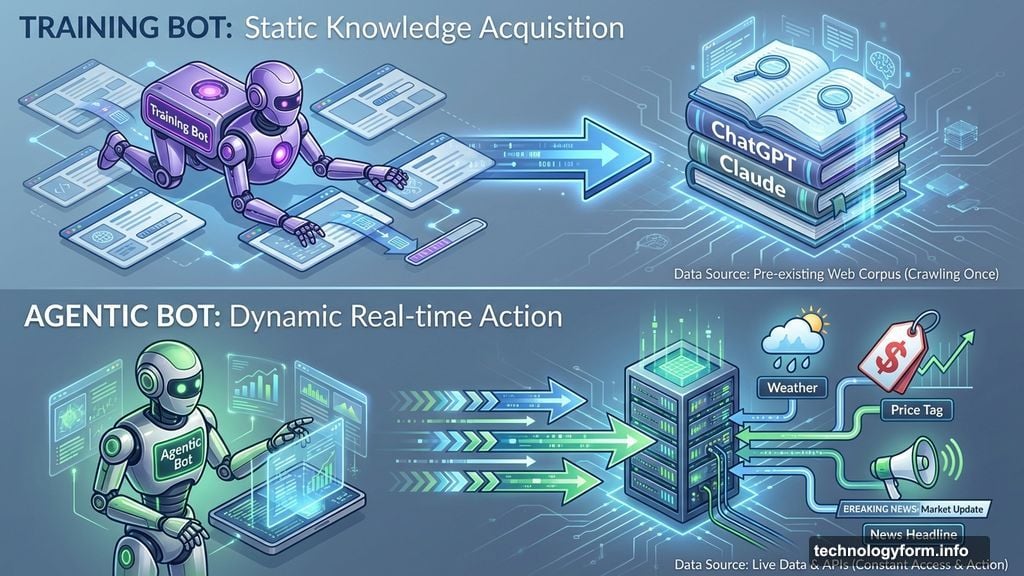
Two Types of AI Bots Are Scraping Everything
Not all AI bots scrape for the same reason. Understanding the difference matters.
Training bots collect massive amounts of web content to train large language models. These bots crawl sites to feed data into systems like ChatGPT or Claude. Publishers hate them because they often ignore copyright protections.
Agentic bots retrieve real-time information to answer specific queries. These bots help AI assistants pull live data—product prices, movie times, breaking news. They’re the reason ChatGPT can tell you today’s weather or summarize recent events.
Both types are exploding in volume. But agentic bots pose a new challenge. They don’t just scrape once for training. They hit websites constantly, fetching fresh data for every user query.
That creates sustained traffic loads. For some sites, AI agents now generate more requests than human visitors. And those requests consume bandwidth, server resources, and money.
Bots Are Getting Sneaky
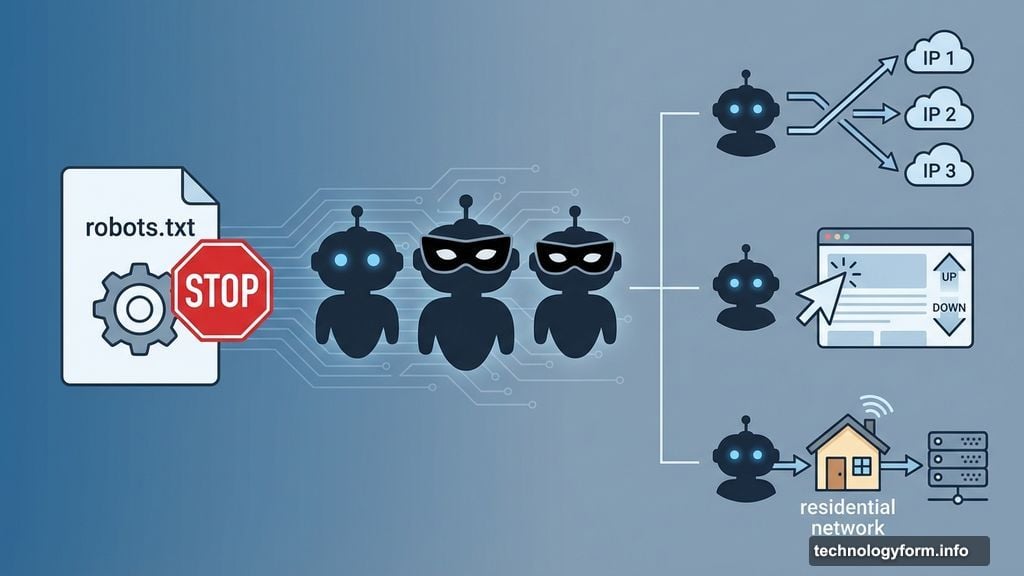
Simple blocking tactics no longer work. AI scrapers now deploy sophisticated evasion techniques.
Some bots disguise their traffic to look like normal web browsers. They mimic human browsing patterns—clicking links, scrolling pages, pausing between requests. This makes them nearly impossible to distinguish from real users.
Others rotate IP addresses constantly. Or they route traffic through residential networks, making it appear like regular home Internet users are accessing sites.

TollBit’s report notes that some AI agents now behave almost identically to humans. Traditional bot detection systems can’t catch them anymore.
“The majority of the Internet is going to be bot traffic in the future,” says Toshit Pangrahi, TollBit’s CEO. “There is a new visitor emerging on the Internet.”
Meanwhile, websites are fighting back. TollBit found a 336 percent increase in sites attempting to block AI bots over the past year. But the bots keep adapting faster than defenses can keep up.
Publishers Face an Existential Crisis
AI scraping threatens business models that depend on human web traffic. And publishers are getting hit hardest.
When bots scrape content, they often don’t display ads. That means zero ad revenue for publishers. Even worse, AI agents can summarize articles directly in chatbots, so users never visit the original site.
Condé Nast and other publishers are suing AI companies over alleged copyright infringement. But litigation takes years. Meanwhile, bot traffic keeps growing.
Some publishers are trying technical solutions. They block known bot user agents. They require login walls. They deploy CAPTCHA challenges.
None of these tactics work consistently. Sophisticated bots bypass them with ease. Plus, blocking too aggressively risks hurting legitimate traffic from search engines and real users.

“Anyone who relies on human web traffic is going to be impacted,” Pangrahi says. “There needs to be a faster way to have that machine-to-machine, programmatic exchange of value.”
A New Industry Emerges
The scraping wars are creating business opportunities. More than 40 companies now sell tools for scraping web content or protecting against scrapers.
TollBit markets systems that let websites charge AI bots for access. Cloudflare offers similar solutions. Other firms help publishers optimize content so AI agents surface it prominently—a strategy called generative engine optimization (GEO).
“We’re essentially seeing the rise of a new marketing channel,” says Uri Gafni of Brandlight, a GEO company. “Search, ads, media, and commerce are converging.”
On the scraping side, firms like Bright Data, ScrapingBee, and Oxylabs sell bot services. These companies argue they provide legitimate tools for cybersecurity research, journalism, and price monitoring.
Or Lenchner, CEO of Bright Data, says his company’s bots don’t collect private information. Oxylabs claims they only scrape publicly accessible content and enforce compliance standards.
But many publishers remain skeptical. They see scraping firms as enablers of copyright infringement, regardless of stated policies.
Robots.txt Is Dying
Robots.txt files have governed bot behavior for decades. Websites use them to specify which pages bots should avoid. Most legitimate bots respected these files—until AI came along.
Now, ignoring robots.txt is becoming standard practice. TollBit’s data shows 13 percent of AI bot requests bypass these files. That percentage keeps rising.
Why? Because AI companies prioritize comprehensive data collection over web etiquette. They want maximum training data or the most current information for agents. Following robots.txt limits what they can scrape.
Some AI companies claim they respect technical boundaries. But those boundaries are often “complex and difficult to follow,” they say. In practice, many bots scrape first and apologize later—if they get caught.
The end of robots.txt compliance marks a significant shift. It suggests AI companies view web content as a commons they can freely harvest, regardless of publisher wishes.
What Comes Next
This arms race will shape the web’s future. Either publishers find ways to monetize or control AI bot access, or they lose the battle entirely.
One scenario involves payment systems that charge bots per request or per data volume. TollBit and similar companies are building this infrastructure. If widely adopted, it could create a new revenue stream for publishers.
Another possibility is stricter legal frameworks. European regulators are already scrutinizing AI scraping practices. US courts may eventually rule on whether mass scraping violates copyright law.
But technology moves faster than legislation. By the time courts decide, AI bots may already dominate web traffic completely.
A third option is content fragmentation. Publishers might retreat behind paywalls and authentication systems that bots can’t penetrate. That would make the open web smaller and less accessible—a loss for everyone.
The Internet Is Becoming a Machine Network
Here’s what frustrates me most about this trend. The web was built for humans. Now it’s rapidly becoming a machine-to-machine network.
AI bots don’t care about user experience. They don’t click ads. They don’t engage with content. They extract data and move on.
If bot traffic continues growing at current rates, websites will optimize for bots instead of humans. That means faster, leaner pages with less design flourish. It means prioritizing machine-readable structured data over rich multimedia experiences.
Publishers face an impossible choice. Block bots and lose visibility in AI systems. Allow bots and sacrifice ad revenue. Try to monetize bots and risk alienating readers with paywalls.
None of these options feel like winning. And the AI companies driving this change don’t seem particularly interested in finding fair solutions.
So we’re left with an escalating conflict. Bots get smarter. Defenses get tougher. Both sides spend more resources on an arms race nobody asked for.
The web is changing whether we like it or not. How we respond now will determine whether it remains a human space or becomes yet another system built for machines first, humans second.