AWS Outage Explained: DNS Error Killed Netflix, Spotify for 70 Minutes
Amazon Web Services went dark. Millions of users suddenly couldn’t access Netflix, Spotify, or Slack. The damage? Potentially $7.6 million in lost revenue for just three companies.
Now AWS finally explained what happened. Turns out, a DNS error triggered a cascade of failures that took nearly a full day to fix completely. Plus, the complexity of modern cloud infrastructure meant fixing one problem revealed another.
Let’s break down what actually went wrong and why it matters for anyone relying on cloud services.
The DNS Domino Effect Started Everything
A DNS issue prevented services from reaching DynamoDB, AWS’s database service for high-speed applications. That means gaming platforms, IoT devices, and ecommerce sites all lost access to critical data storage simultaneously.
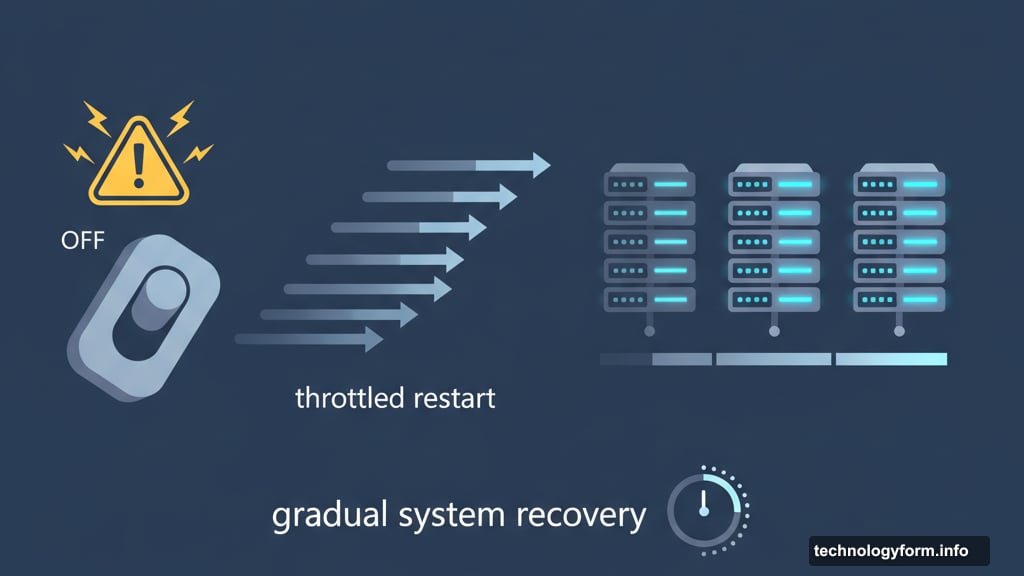
But here’s where it gets worse. An internal EC2 subsystem also failed because it depended on DynamoDB. So fixing the DNS problem didn’t immediately restore services. Instead, AWS had to carefully restart systems to avoid overwhelming the infrastructure.

Think of it like turning the power back on after a blackout. You can’t flip every switch at once. Otherwise, you’ll just blow the grid again. AWS had to take a throttled approach, gradually bringing services back online.
Why Full Recovery Took Nearly 24 Hours
AWS resolved the initial DNS issue relatively quickly. Services started recovering around that time. However, the EC2 subsystem failure created a bottleneck.
Moreover, some services built up massive backlogs during the outage. AWS Config, Redshift, and Connect had queues of messages waiting to process. Even after core systems came back, these services needed hours to work through their backlog.
By 3:01 PM PT, AWS declared everything “fully restored.” Yet they admitted some services would still process delayed messages for several more hours. That’s not exactly a clean recovery.
Cybercriminals Exploited the Chaos

Cybernews Senior Journalist Stefanie Schappert called this a “perfect storm” for cyberattacks. Criminals typically exploit widespread panic to push malicious campaigns that feel urgent.
During major outages, users desperately want solutions. So they’re more likely to click suspicious links promising to fix problems. That makes outages prime time for phishing attacks, malware distribution, and credential theft.
Schappert’s advice? Don’t click any links in emails, texts, or pop-ups claiming to fix outage issues. If a service is down, wait for official announcements through verified channels. No legitimate company sends random emails during outages asking you to click emergency links.
The Real Cost of Cloud Dependency
DesignRush calculated the financial damage. Netflix potentially lost $4.5 million in revenue during those 70 minutes. Spotify might’ve lost $2 million. Salesforce’s Slack outage could’ve cost them $1.13 million.
These are just estimates. But they illustrate how expensive cloud failures become when major platforms go dark. Plus, these numbers only cover three companies. Hundreds of other businesses also lost revenue during the outage.

DesignRush’s Anonta Khan made a crucial point. More than half of the Fortune 500 depend on AWS. When a single provider fails, the ripples spread throughout the entire economy. That’s the hidden risk of cloud concentration.
What AWS Didn’t Say
Amazon’s status page explanation focused on technical details. DNS error, DynamoDB dependency, EC2 subsystem failure. All accurate. But it avoided bigger questions.
Why did a DNS error cause such widespread cascading failures? Why couldn’t redundancy systems prevent the outage? How can customers trust AWS won’t experience similar issues again?
AWS built its reputation on reliability. But this incident shows how interconnected modern cloud systems have become. One small DNS problem shouldn’t knock out major services for hours. Yet it did.
Companies relying entirely on AWS now face uncomfortable questions. Is single-cloud dependency too risky? Should they invest in multi-cloud strategies despite higher costs? How much downtime can their business actually survive?
The Multi-Cloud Dilemma Gets Harder
Many experts recommend multi-cloud strategies to avoid vendor lock-in. Spread your infrastructure across AWS, Google Cloud, and Microsoft Azure. Then if one fails, your services keep running.
Sounds great in theory. But it’s expensive and complex. You need specialists for multiple platforms. Data transfers between clouds cost serious money. Plus, your architecture becomes significantly more complicated to manage.
Still, this outage makes that investment look more reasonable. Netflix, Spotify, and Slack all lost money because they couldn’t quickly pivot to backup providers. Companies watching this incident will reconsider their cloud strategy. Some will decide multi-cloud complexity beats single-provider risk.
The irony? AWS’s own complexity contributed to this outage. More abstraction layers mean more potential failure points. Adding multiple cloud providers creates even more complexity. There’s no simple answer here.
Choose carefully. Understand your actual downtime tolerance. Calculate what outages cost your business. Then decide if single-cloud simplicity or multi-cloud resilience makes more sense for your specific situation.