
Multiverse Computing Wants to Free AI From the Cloud
The cloud isn’t always the answer. And one Spanish startup is betting businesses are starting to figure that out.
Multiverse Computing just made a quiet but meaningful move. The company launched a self-serve API portal giving developers and enterprises direct access to its compressed AI models — no AWS Marketplace required. Combined with its CompactifAI app, this positions Multiverse as a serious contender in the growing race to run powerful AI on smaller, cheaper, and more private infrastructure.
The timing couldn’t be better.
Compute Risk Is Real, and Businesses Are Nervous
Earlier this year, VC firm Lux Capital issued a stark warning. With private company defaults running above 9.2% — the highest in years — Lux advised any company relying on AI to get its compute capacity commitments in writing. A handshake agreement, they said, isn’t enough when financial instability is rippling through the AI supply chain.
That’s a real problem for companies betting their operations on cloud-based AI. Dependency on external infrastructure means exposure to pricing changes, service interruptions, and counterparty risk. So the idea of running AI directly on your own hardware — with no data center middleman — is starting to sound a lot more attractive.

Multiverse Computing has been quietly working on exactly that.
Compressed AI Models That Fit in Your Pocket
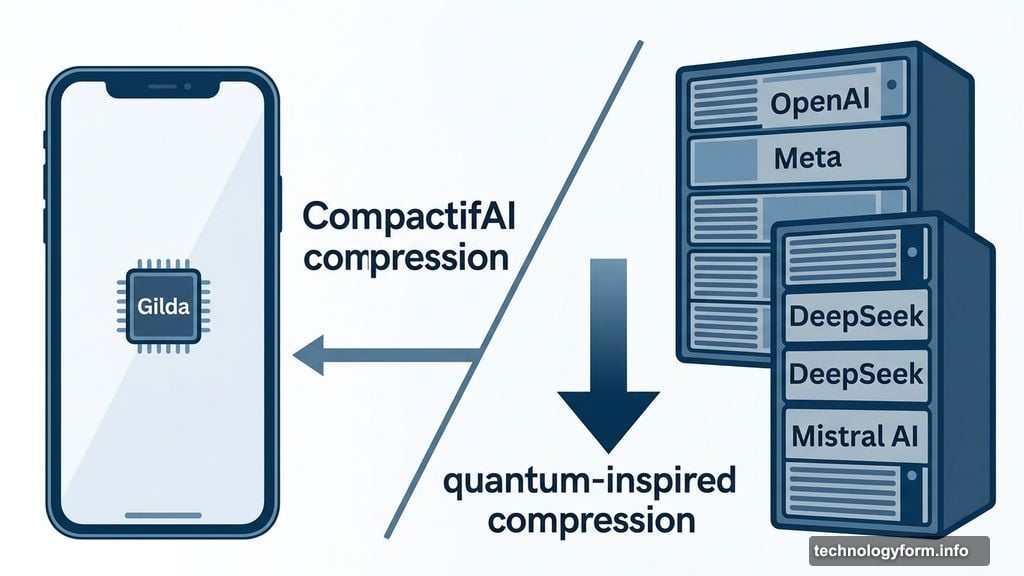
The company’s core technology is called CompactifAI — a quantum-inspired compression technique that shrinks AI models from major labs, including OpenAI, Meta, DeepSeek, and Mistral AI, down to a fraction of their original size. The goal is to keep the useful parts of a large model while cutting the computational fat.
The flagship demo of this technology is Gilda, a model small enough to run locally on a mobile device without any internet connection. Multiverse embedded Gilda into a consumer-facing chat app, also called CompactifAI, that works a bit like ChatGPT — ask a question, get an answer.
The difference is that your data never leaves your phone.
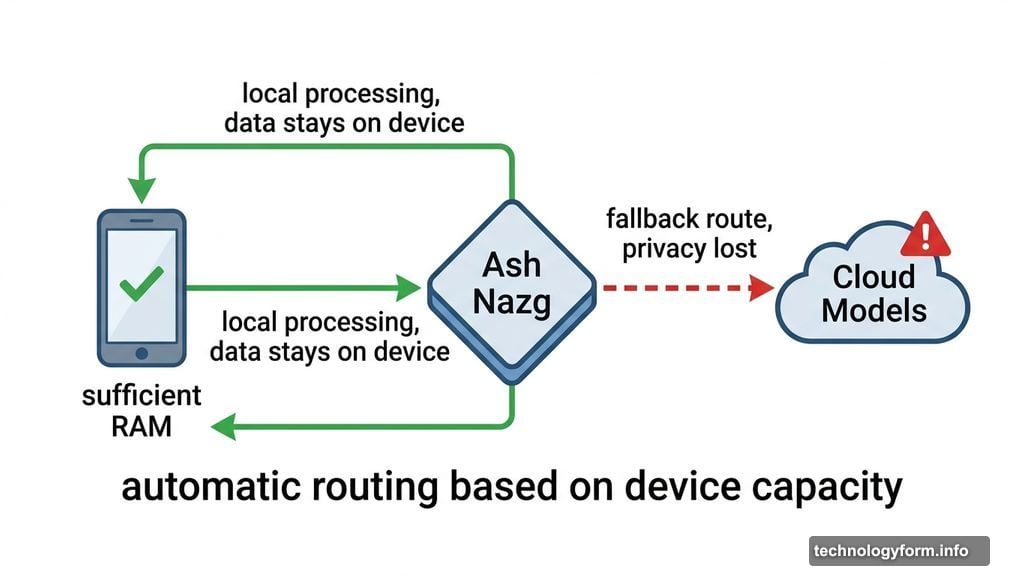
There’s a catch, though. If your device doesn’t have enough RAM and storage — and many older iPhones don’t — the app automatically routes requests to cloud-based models instead. A system Multiverse named “Ash Nazg” handles this routing automatically. Tolkien fans will recognize the reference immediately: it’s the inscription on the One Ring from “The Lord of the Rings.”
When the app falls back to the cloud, though, the privacy advantage disappears. And with fewer than 5,000 downloads in the past month according to Sensor Tower data, the consumer app is clearly not the main event. It’s more of a proof of concept.
The real target is enterprise customers.
On-Device AI Opens Doors Regular Cloud Models Can’t
For most businesses, the pitch for compressed models comes down to three things: cost, privacy, and resilience.
Cost is obvious. Running AI on-device or on local hardware is dramatically cheaper than paying per API call to a large language model (LLM). Real-time usage monitoring is a key feature of Multiverse’s new API portal — and that’s deliberate. Companies want visibility into exactly what they’re spending before committing to a deployment.
Privacy matters more in some industries than others. For workers in healthcare, finance, legal, or government contexts, keeping data entirely on-device isn’t just a preference — it’s often a requirement. A model that runs locally and never touches an external server is genuinely valuable in those settings.
But the most interesting use case is resilience. Think about deploying AI in drones, satellites, or remote industrial equipment. These systems can’t always phone home to a cloud server. A model that works without a connection isn’t just convenient in those situations — it’s essential.
Multiverse already serves more than 100 global customers, including the Bank of Canada, Bosch, and Iberdrola. These aren’t companies experimenting casually with AI. They’re running serious workloads and they need reliability.
The Gap Between Small Models and Large Ones Is Shrinking Fast
One of the biggest objections to small models has always been performance. Why use a compressed model when a full-sized LLM can do so much more?
That gap is closing. Mistral just updated its small model family with Mistral Small 4, which the company says is simultaneously optimized for general chat, coding, agentic tasks, and reasoning. Mistral also released Forge, a system that lets enterprises build custom small models and choose the trade-offs that fit their specific use cases.
Multiverse’s own results point in the same direction. Its latest model, HyperNova 60B 2602, is built on gpt-oss-120b — an OpenAI model whose underlying code is publicly available. Multiverse claims HyperNova now delivers faster responses at lower cost than the original, which is a striking claim. The advantage matters especially for agentic coding workflows, where AI autonomously handles complex, multistep programming tasks without human direction at each stage.
That’s not a niche capability. Autonomous coding agents are increasingly central to how software teams work, and speed matters enormously in those pipelines.
Apple Already Solved Part of This Problem
Multiverse isn’t the only company wrestling with the challenge of running capable AI on constrained hardware. Apple Intelligence handles the same tension by splitting tasks between an on-device model and a cloud model, routing requests based on complexity.
Multiverse’s CompactifAI app does something similar with its Ash Nazg routing system. But Multiverse’s ambitions extend beyond the consumer use case that Apple is targeting. The company wants to push AI into environments where even Apple’s hybrid approach wouldn’t work — places with no reliable connectivity at all.
Making models small enough to be useful on a mobile device or embedded system while still being genuinely capable is hard. It’s one of the toughest problems in applied AI right now. Multiverse’s argument is that quantum-inspired compression gets closer to solving it than most approaches.
Funding Ambitions Match the Scale of the Vision
After raising a $215 million Series B last year, Multiverse is reportedly working on a fresh €500 million funding round at a valuation of more than €1.5 billion. That’s a significant step up and signals the company believes it’s building something with serious commercial legs.
The new API portal is part of that story. Self-serve developer access lowers the barrier to trying Multiverse’s models. More developers experimenting means more enterprise leads. More enterprise leads means more revenue data to support a fundraise at that kind of valuation.
The strategy makes sense. The compressed models space is getting crowded, but Multiverse has a technical differentiation story, a real customer base, and timing that works in its favor. Businesses are actively looking for alternatives to expensive, risky cloud dependency.
Whether Multiverse can scale fast enough to capitalize on that moment is the open question. But the pieces are moving in the right direction.





