
Wikipedia Just Banned AI-Generated Content. Here’s What’s Still Allowed
For 25 years, Wikipedia has run on a simple promise: anyone can contribute, as long as the information is accurate and verifiable. Now the platform is putting that promise to the test against one of the biggest threats to online accuracy it has ever faced.
Wikipedia officially banned the use of large language models (LLMs) to generate or rewrite article content. The policy calls out ChatGPT and Google Gemini by name. And while the rule comes with a couple of narrow exceptions, the message is clear: human knowledge, not AI output, is what belongs on Wikipedia.
Why LLMs Earned Wikipedia’s Distrust
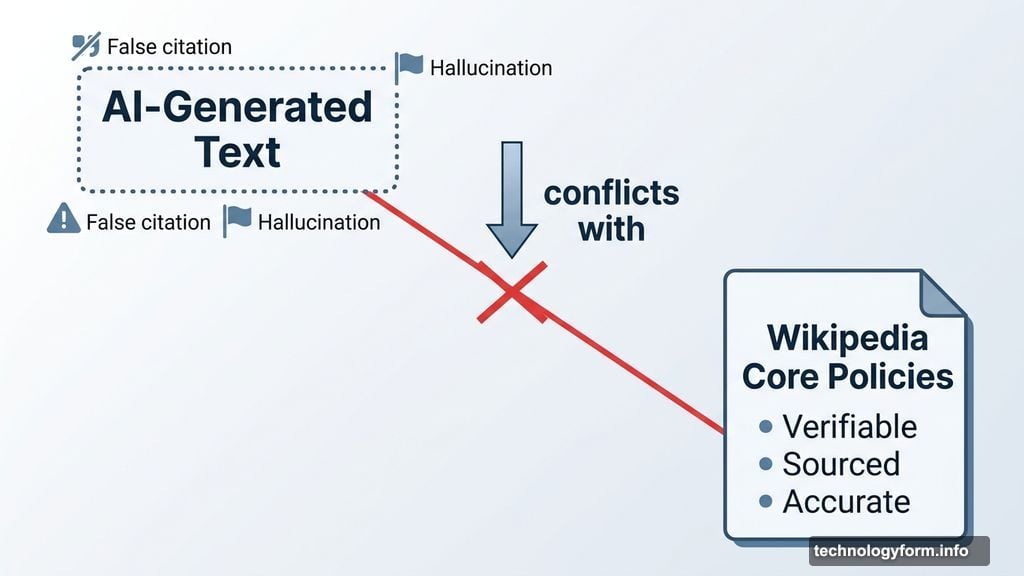
Wikipedia’s editing policy doesn’t mince words. It states that “text generated by large language models often violates several of Wikipedia’s core content policies.” That’s a serious accusation from a platform that has always welcomed open contributions.
The concern makes sense when you think about how LLMs work. These models generate text that sounds confident and polished, but they don’t actually verify facts. They predict likely word sequences based on training data. So they can produce plausible-sounding nonsense, misattribute quotes, and invent citations that don’t exist.

Wikipedia’s entire foundation rests on verifiable, sourced information. AI-generated text fundamentally conflicts with that standard. Plus, there are real plagiarism risks, since LLMs sometimes reproduce copyrighted content without attribution.
The Two Exceptions Wikipedia Actually Allows
The ban isn’t absolute. Wikipedia carved out two specific situations where AI assistance remains permitted.
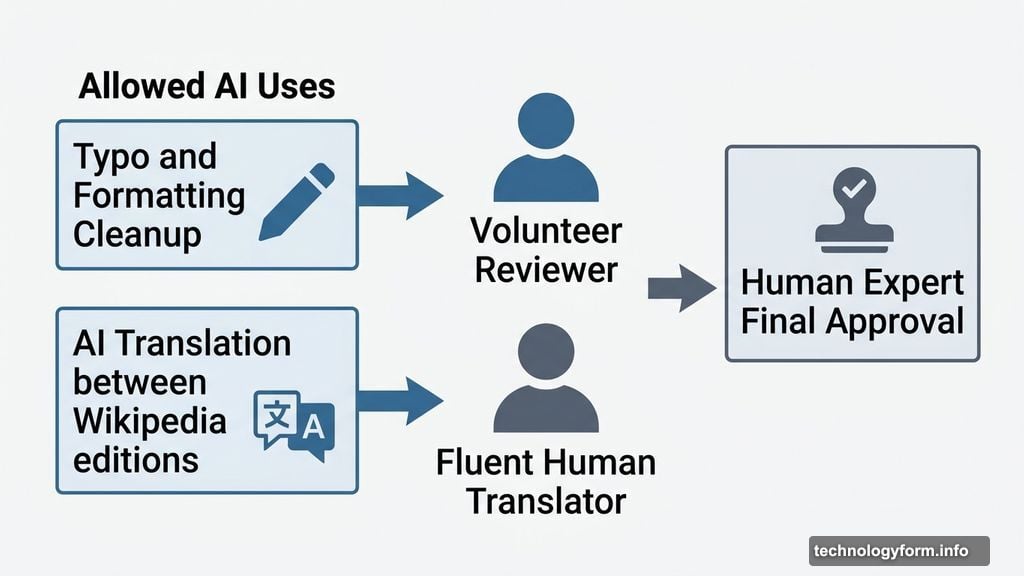
First, editors can use AI for basic cleanup tasks. Think fixing typos or adjusting formatting. But there’s a catch. This only applies to articles the editor originally wrote themselves, and a Wikipedia volunteer reviewer or administrator must review the edits first. Even then, Wikipedia warns that AI can subtly shift the meaning of content in ways that might not align with the original source’s intent.
Second, AI translation is allowed under strict conditions. Editors can use AI to translate articles from other-language Wikipedia editions into English. However, the translator must be fluent in both languages. Wikipedia isn’t handing translation duties entirely to the machine. It’s using AI as a tool while keeping a qualified human in charge of accuracy.
Both exceptions share a common thread: a human expert stays responsible for the final result.
Enforcement Remains a Wide-Open Question
Here’s where things get complicated. Wikipedia hasn’t explained how it plans to enforce this policy, or what happens to editors who break the rules.
That’s a real challenge. AI-generated text isn’t always easy to spot. Detection tools exist, but they’re imperfect. A skilled editor could clean up AI output enough to pass casual review. And with Wikipedia relying heavily on volunteer moderators, consistent enforcement across millions of articles seems difficult at best.
Wikipedia also hasn’t said when the policy officially took effect. A representative didn’t respond to CNET’s request for comment, so the timeline remains unclear.
This isn’t the first time Wikipedia has pushed back against AI companies, either. Last year, the Wikimedia Foundation asked AI companies to stop scraping Wikipedia’s data directly and instead use its Enterprise API. The foundation argued the API allows AI companies to access content at scale without hammering Wikipedia’s servers, while also supporting Wikipedia’s nonprofit mission. That request appears to have had limited impact on actual scraping behavior.
A Broader Fight Over Who Controls Knowledge Online
Wikipedia’s decision lands during a moment of real tension across the internet. AI features now come baked into smartphones through tools like Apple Intelligence and Samsung’s Galaxy AI. Websites, apps, and services increasingly rely on AI-generated content to fill pages faster and cheaper than human writers can.
But mounting evidence shows that AI hallucinations, where models confidently state false information, remain a stubborn problem without a clear technical fix. For a reference source like Wikipedia, where readers worldwide trust the content to be accurate, that risk is simply unacceptable.
Wikipedia’s stance reflects something worth paying attention to. Speed and convenience matter, but not more than truth. Human judgment, editorial standards, and verifiable sourcing still have to win when accuracy is on the line.
Whether Wikipedia can actually enforce that standard at scale is another question entirely. The policy sets the right intention. Making it stick will be the hard part.





