
Cloudflare’s Massive Outage Just Broke Half the Internet
The internet essentially stopped working this morning for millions of users worldwide. Cloudflare, the infrastructure backbone powering countless websites, crashed hard.
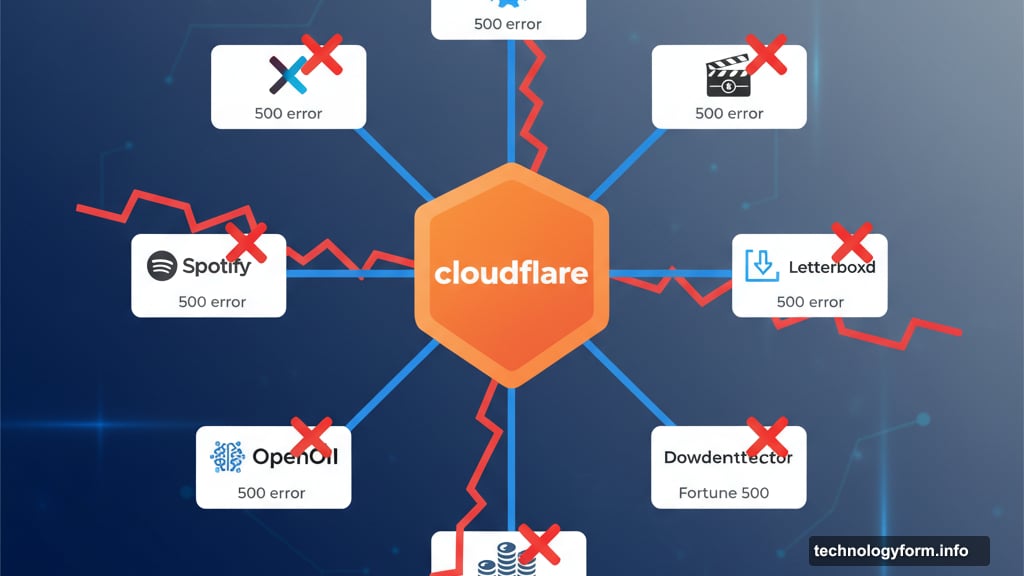
Starting around 7AM ET, websites across the globe displayed “500 internal server error” messages. X, Spotify, OpenAI, Letterboxd, and even Downdetector itself went dark. That’s right. The site that tells you what’s broken was broken too.
What Actually Happened
Cloudflare reported “widespread 500 errors” affecting both its dashboard and API systems. The company acknowledged the problem quickly but offered few details initially.
For context, Cloudflare isn’t just another tech company. It’s a critical internet hub providing network infrastructure, security tools, and edge computing services. Fortune 500 companies, internet service providers, and major websites depend on it to stay online during cyberattacks and traffic spikes.
So when Cloudflare goes down, massive chunks of the internet go with it.
The Recovery Timeline
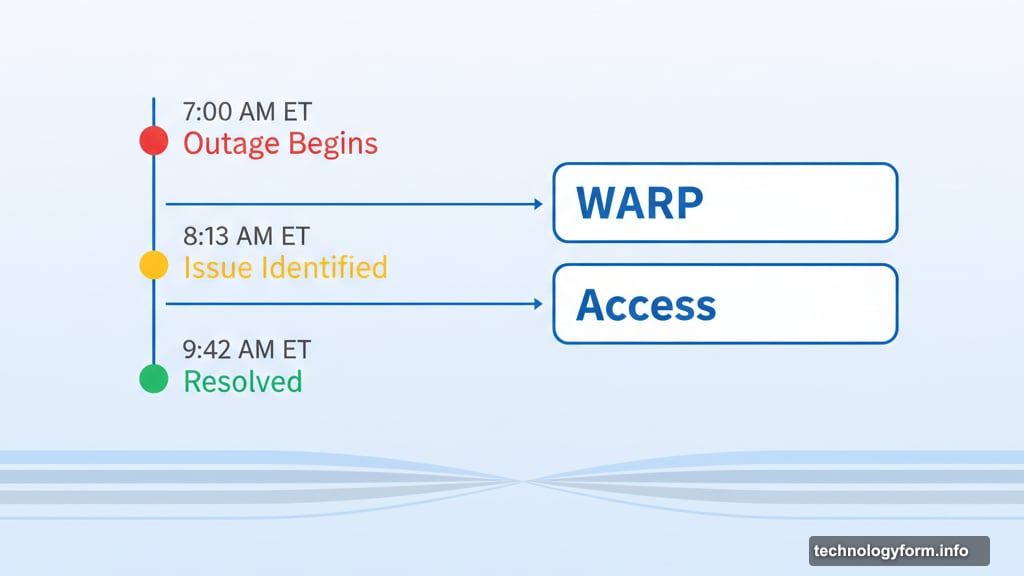
Cloudflare identified the issue around 8:13AM ET. At that point, the company implemented fixes that restored its WARP and Access services first. Those tools provide clients with speedy, secure connections to Cloudflare’s network.
By 9:42AM ET, Cloudflare declared “we believe the incident is now resolved.” The company confirmed it would monitor for additional disruptions throughout the day.
CTO Dane Knecht posted an apology on X, promising a detailed explanation later. He also clarified that this wasn’t a cyberattack. Instead, it was an internal failure within Cloudflare’s own systems.
“I won’t mince words: earlier today we failed our customers and the broader Internet,” Knecht wrote. “The sites, businesses, and organizations that rely on Cloudflare depend on us being available and I apologize for the impact that we caused.”
Why This Matters More Than You Think
Cloudflare’s role in internet infrastructure makes outages like this particularly dangerous. The company protects websites from distributed denial of service (DDoS) attacks and helps them handle massive traffic loads.
When Cloudflare fails, websites lose those protections instantly. Plus, the cascading effect disrupts services that seemingly have nothing to do with each other. A social media platform, a music streaming service, and an AI chatbot all went down simultaneously because they share the same infrastructure provider.
That concentration of critical services creates a single point of failure. One problem at Cloudflare ripples across the entire internet ecosystem.
Sites Slowly Came Back Online
Downdetector showed X and Spotify returning to normal functionality by mid-morning. However, many Engadget editors still couldn’t access X even after Cloudflare announced the fix.
That’s typical for this type of outage. Recovery happens in waves as systems restart and caches rebuild. Some users regain access immediately while others wait hours for full restoration.
Moreover, the “fix is being implemented” language suggests Cloudflare rolled out changes gradually rather than flipping a single switch. That cautious approach prevents making the situation worse but extends downtime for some users.
The Real Problem Nobody Wants to Discuss
Internet infrastructure has become dangerously centralized. Cloudflare, AWS, Google Cloud, and a handful of other companies now control most of the internet’s critical backbone.
That concentration creates efficiency and cost savings. But it also means single failures can take down huge portions of the web simultaneously. No redundancy exists when everyone uses the same provider.
Plus, these outages are becoming more frequent. Cloudflare experienced similar issues in 2019 and 2022. Amazon’s AWS has had multiple major outages. Google Cloud went down last year, taking Discord, Spotify, and Snapchat offline.
Each incident reminds us how fragile our internet infrastructure really is. Yet companies continue consolidating rather than diversifying their providers.
What You Can Actually Do
Not much, honestly. Individual users can’t protect themselves from infrastructure-level failures. When Cloudflare goes down, your VPN won’t help. Your home network is fine. The problem exists far beyond your control.
Businesses have slightly more options. They can use multiple CDN providers or implement failover systems. But those solutions cost money and add complexity. Most companies choose convenience and cost savings over redundancy.
That leaves us dependent on a small number of infrastructure giants to keep the internet running. When they fail, we all suffer the consequences together.
The internet worked fine for most people by late morning. Still, this outage raises uncomfortable questions about how we’ve built our digital infrastructure. We’ve traded resilience for efficiency, and mornings like this are the price we pay.





