AI Jargon Explained: Your Plain-English Guide to the Terms Everyone’s Using
Artificial intelligence is everywhere right now. But the language around it? That’s another story.
Researchers, developers, and tech journalists toss around terms like “LLMs,” “hallucinations,” and “chain of thought” as if everyone already knows what they mean. Most people don’t. And honestly, that’s fine. These are genuinely complex ideas wrapped in unnecessarily complicated packaging.
So let’s fix that. Here’s a straightforward breakdown of the most important AI terms you’ll encounter, explained the way a knowledgeable friend would explain them over coffee.
AGI: The Holy Grail Nobody Can Quite Define
Artificial general intelligence, or AGI, is one of the most talked-about concepts in tech right now. But here’s the thing: even the experts can’t fully agree on what it means.
OpenAI CEO Sam Altman describes AGI as the equivalent of “a median human that you could hire as a co-worker.” OpenAI’s official charter goes a bit further, defining it as systems that “outperform humans at most economically valuable work.” Google DeepMind takes a slightly different angle, calling it AI that’s “at least as capable as humans at most cognitive tasks.”
So which definition is right? All of them, sort of. That’s the problem. AGI remains a moving target, and even leading researchers disagree about where the finish line sits.
Large Language Models (LLMs): The Brains Behind the Chatbots
When you chat with ChatGPT, Claude, Gemini, or Microsoft Copilot, you’re interacting with a large language model. LLMs are the actual AI systems doing the heavy lifting behind these popular tools.
Think of an LLM as an incredibly well-read entity that has absorbed billions of books, articles, and web pages. It learned the patterns of language from all that reading. So when you ask it something, it predicts the most likely sequence of words that would form a useful response.
It doesn’t “think” the way you do. Instead, it’s calculating probabilities at lightning speed. Next word, next word, next word. The results can feel surprisingly human, even though the process underneath is purely mathematical.

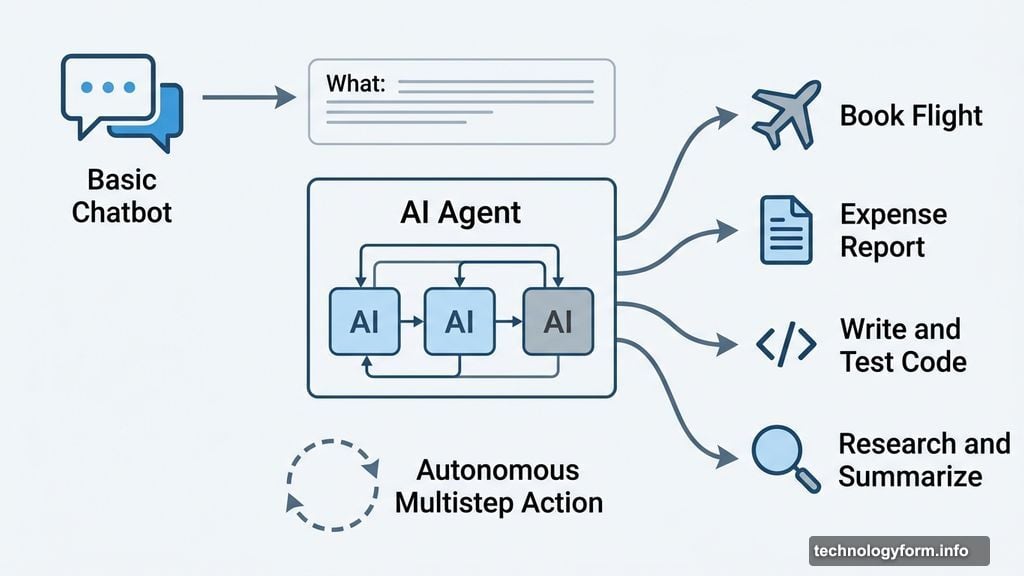
AI Agents: More Than Just Chatbots
A basic chatbot answers questions. An AI agent actually does things on your behalf.
Book a flight, file an expense report, write and test code, research a topic and compile a summary. These are the kinds of multistep tasks AI agents are being built to handle. They often combine multiple AI systems working together to complete a goal.
The technology is still evolving fast. So “AI agent” means slightly different things depending on who you ask. But the core idea is an autonomous system that acts rather than just responds.
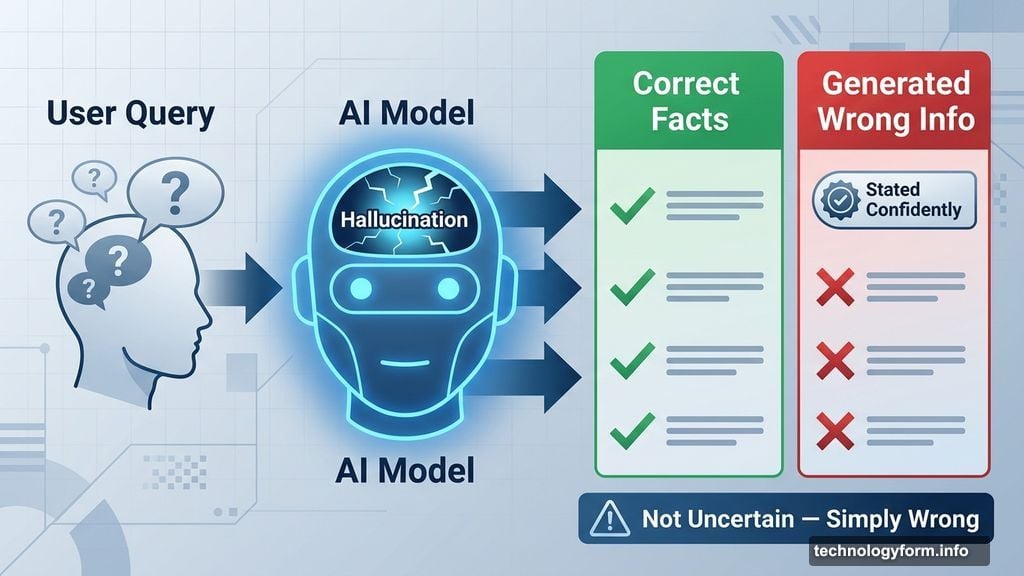
Hallucination: When AI Confidently Makes Things Up
This is one of the most important terms to understand. Hallucination describes what happens when an AI model generates information that is simply wrong. Not uncertain. Not vague. Just factually incorrect, stated with full confidence.
Why does it happen? Gaps in training data. AI models learn from enormous datasets, but those datasets can’t cover everything. When a model encounters a question that pushes beyond what it learned, it fills in the blanks rather than admitting it doesn’t know.
The consequences can range from mildly annoying to genuinely dangerous. Imagine asking an AI about medication dosages and receiving harmful medical advice presented as fact. That’s why most AI tools now include small print warning users to verify AI-generated answers. But those disclaimers often appear much less prominently than the answers themselves.
Chain of Thought: Slowing Down to Think More Carefully
Some problems need working-through, not just quick answers. That’s where chain-of-thought reasoning comes in.
Here’s a simple example. A farmer has chickens and cows. Together they have 40 heads and 120 legs. How many of each? You’d probably grab a pen and work through the math step by step before arriving at the answer (20 chickens, 20 cows). Chain-of-thought reasoning asks AI to do the same thing: break problems into smaller intermediate steps before reaching a conclusion.
The result takes longer. But it’s significantly more accurate, especially for logic problems and coding tasks. Reasoning models, a newer category of AI, are specifically designed and optimized for this kind of step-by-step thinking.
Training vs. Inference: Building the Brain vs. Using It
These two terms describe different phases of an AI model’s life, and they’re worth keeping separate.
Training is how an AI model learns. You feed it massive amounts of data. It identifies patterns. It adjusts its internal settings repeatedly until its outputs start matching what you want. Before training, a model is essentially just a mathematical structure full of random numbers. Training gives it meaning.
Inference is what happens when you actually use a model. It’s the AI taking what it learned and applying that knowledge to new inputs. When you type a question into ChatGPT and receive an answer, that’s inference happening in real time.
Training is expensive and slow. Inference needs to be fast. These different demands shape many of the biggest decisions in how AI systems get built and deployed.
Neural Networks: Borrowing Ideas from the Human Brain
A neural network is the architectural foundation that makes modern AI possible. The concept has been around since the 1940s, but it only became truly powerful when GPU chips (originally developed for video games) made it feasible to train much larger, more complex versions.
The basic idea comes from biology. Human brains consist of billions of neurons connected in intricate networks. These connections strengthen or weaken based on experience. Neural networks borrow this design principle and apply it to data processing.
Layers upon layers of interconnected mathematical operations allow these systems to recognize patterns in images, understand spoken language, predict protein structures, and much more. Deep learning, a more complex subset of this approach, stacks even more layers together to handle even harder problems.
Tokens: The Building Blocks of AI Communication
Humans communicate in words and sentences. AI models work in tokens.
A token is roughly equivalent to a word, though not exactly. Sometimes it’s a whole word, sometimes just part of one. When you send a message to an AI, it gets broken down into tokens first. The model processes those tokens and generates output tokens in response.
Why does this matter practically? Because tokens are also how AI companies charge for their services. Most providers bill businesses on a per-token basis. The more tokens a company’s applications consume, the higher the bill. So understanding tokens helps make sense of AI pricing and efficiency.
Weights: What an AI Actually Learns
When people say an AI model “learned” something, weights are what actually changed inside the system.
Weights are numerical values assigned to different features in the training data. They determine how much importance the model places on each piece of information when generating responses. Training starts with random weights. As the model processes data and receives feedback on its outputs, those weights adjust. Gradually, the model gets better.
Here’s a concrete example. An AI trained to predict housing prices might assign high weights to the number of bedrooms and neighborhood location. It might assign low weights to less relevant features like paint color. The weights reflect what actually matters for the task at hand.
Fine-Tuning and Transfer Learning: Shortcuts Worth Knowing
Building a powerful AI model from scratch is expensive and time-consuming. Fine-tuning and transfer learning offer smarter alternatives.
Transfer learning means taking a model that was already trained on a broad task and using it as the starting point for a more specific one. Think of it as hiring someone with great general skills and then training them specifically for your industry.
Fine-tuning goes a step further. You take that pre-trained model and continue training it on specialized data relevant to your specific use case. Many AI startups do exactly this: they start with a powerful LLM and fine-tune it with their own domain expertise. The result is a more focused, more useful product built on a solid foundation.
Diffusion: How AI Creates Images and Art
Behind most AI image generators, music creators, and text-to-art tools sits a concept called diffusion. The name comes from physics.
Imagine taking a clear photograph and slowly adding random visual noise until the image becomes pure static. Diffusion AI models learn to run this process in reverse. They start with noise and gradually sculpt it into a coherent image. Through training, they develop an understanding of what “realistic photo” or “oil painting” or “cartoon character” looks like well enough to recover those patterns from randomness.
It’s a surprisingly elegant approach, and it powers many of the most impressive AI creative tools available today.
GANs: The Original AI Art Makers
Before diffusion became dominant, Generative Adversarial Networks, or GANs, were the main technology behind AI-generated images and deepfakes.
GANs pit two neural networks against each other. The first, called the generator, creates artificial images. The second, the discriminator, tries to detect which images are fake. They train together in a kind of competitive loop: the generator keeps trying to fool the discriminator, while the discriminator keeps getting better at spotting fakes. The result is increasingly realistic outputs over time.
GANs work best for specific, narrower tasks like generating realistic faces or altering video footage. They’re less suited to general-purpose creative work, which is one reason diffusion models have largely taken over for broader applications.
Compute: The Fuel Powering the Entire Industry
“Compute” is tech shorthand for the raw processing power that makes AI work. Think GPUs, CPUs, specialized AI chips called TPUs, and the massive data center infrastructure that houses all of them.
Training a state-of-the-art AI model requires enormous amounts of compute. Running that model at scale requires even more. The companies that control the most compute hold significant advantages in the AI race. That’s why access to high-end chips has become one of the most strategically important resources in the entire technology industry.
Distillation: Teaching Small Models to Punch Above Their Weight
Distillation is a technique for creating smaller, more efficient AI models by learning from larger, more powerful ones.
The process works like a teacher-student relationship. The larger “teacher” model generates responses to a huge range of inputs. Those responses get used to train a smaller “student” model to approximate the teacher’s behavior. Done well, the student model can perform surprisingly close to the teacher’s level at a fraction of the computational cost.
This is likely how OpenAI developed GPT-4 Turbo, a faster and leaner version of the original GPT-4. Worth noting: using a competitor’s model as the teacher generally violates terms of service, though that hasn’t stopped some companies from trying.
Memory Cache and KV Caching: Speeding Things Up
Every time an AI model processes a request, it performs complex mathematical calculations. Those calculations take time and consume power. Memory caching is a technique designed to reduce that burden.
The idea is simple: save certain calculations so they don’t have to be repeated from scratch. One well-known approach is KV (key-value) caching, which works within transformer-based models. When you’re having a long conversation with an AI, the model doesn’t need to re-process everything you said earlier every single time. KV caching stores that prior context so the model can skip steps it’s already completed.
The result is faster responses and more efficient use of resources, which matters enormously when serving millions of simultaneous users.
RAMageddon: The Memory Shortage Nobody Saw Coming
The term “RAMageddon” sounds dramatic. Unfortunately, it describes a genuinely disruptive trend.
RAM, or random access memory, powers virtually every tech product we use. As the AI industry has exploded, major tech companies and AI labs are buying RAM chips in staggering quantities to power their data centers. The demand has grown so fast that supply can’t keep up.
The ripple effects are widespread. Gaming console makers face higher production costs. Consumer electronics companies are dealing with a potential dip in smartphone shipments. Enterprise businesses can’t get enough memory for their own infrastructure needs. And prices keep climbing. Industry observers don’t see relief coming anytime soon.
Deep Learning: Why Modern AI Is So Much Better
Deep learning is the specific approach to machine learning that made the current AI boom possible.
Traditional machine learning required human engineers to define which features of data were important. Deep learning models figure that out themselves. They use multi-layered neural network structures inspired by the brain’s own architecture to identify patterns at multiple levels of abstraction simultaneously.
The tradeoff? Deep learning models need enormous amounts of data and significant compute to train well. But when those conditions are met, the results are remarkable. Voice recognition, medical image analysis, autonomous driving, protein structure prediction. Deep learning drives all of it.
The AI landscape moves fast, and new terminology keeps emerging alongside new techniques. But understanding these core concepts gives you a solid foundation for following the developments that matter, whether you’re evaluating AI tools for your work, following the latest research, or just trying to understand what everyone’s talking about.





