Anthropic Built an AI to Review the Code Its AI Writes
AI is generating code faster than humans can check it. Now Anthropic wants to fix that problem with another AI.
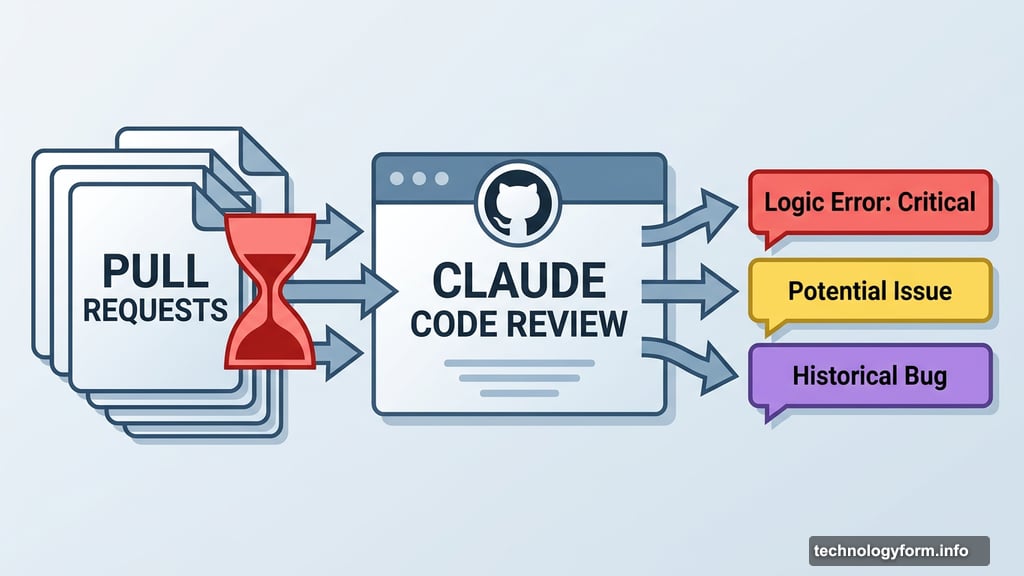
The company launched Code Review on Monday, a new feature inside Claude Code designed to automatically catch bugs, logic errors, and security issues in AI-generated pull requests before they make it into production. It’s landing first for Claude for Teams and Claude for Enterprise customers as a research preview.
Vibe Coding Created a Pull Request Bottleneck
The rise of so-called “vibe coding” changed software development fast. Developers now describe what they want in plain language, and AI tools like Claude Code generate large chunks of working code almost instantly.
That speed comes with a catch. More code means more pull requests. And more pull requests mean longer review queues.
“One of the questions we keep getting from enterprise leaders is: Now that Claude Code is putting up a bunch of pull requests, how do I make sure that those get reviewed in an efficient manner?” Cat Wu, Anthropic’s head of product, told TechCrunch.
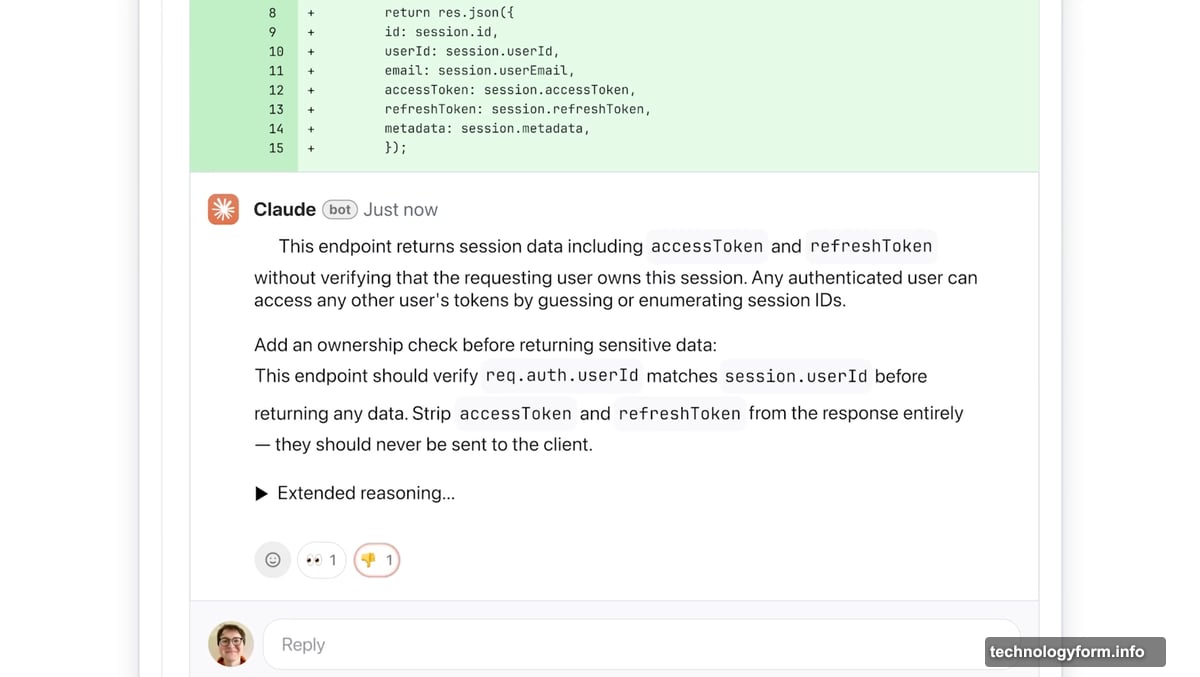
Pull requests are the mechanism developers use to submit code changes for review before those changes officially enter a codebase. When AI dramatically speeds up output, the review step becomes the new bottleneck. Code Review is Anthropic’s direct answer to that problem.
Logic Errors Over Style Complaints
Here’s what makes this tool different from AI code feedback developers have seen before. Anthropic deliberately focused on logic errors instead of style suggestions.
That might sound like a small detail. But it’s actually the reason most developers hate automated code review tools. Nobody wants a bot flagging variable naming conventions when there’s a potential security hole sitting three lines down.
“This is really important because a lot of developers have seen AI automated feedback before, and they get annoyed when it’s not immediately actionable,” Wu said. “We decided we’re going to focus purely on logic errors. This way we’re catching the highest priority things to fix.”
Once enabled, Code Review integrates directly with GitHub and automatically analyzes pull requests. It leaves comments directly on the code, explaining what the potential issue is, why it matters, and how to fix it. The AI walks through its reasoning step by step, which helps developers actually learn from the feedback rather than just dismissing it.
![Screenshot of Anthropic’s Claude Code interface showing the Code Review feature highlighting a logic error in a GitHub pull request with color-coded severity labels]
Color-Coded Severity and Multi-Agent Architecture
The tool labels issues by severity using a color system. Red flags the highest-priority problems. Yellow marks potential issues worth a closer look. Purple highlights bugs tied to existing code or historical problems in the codebase.
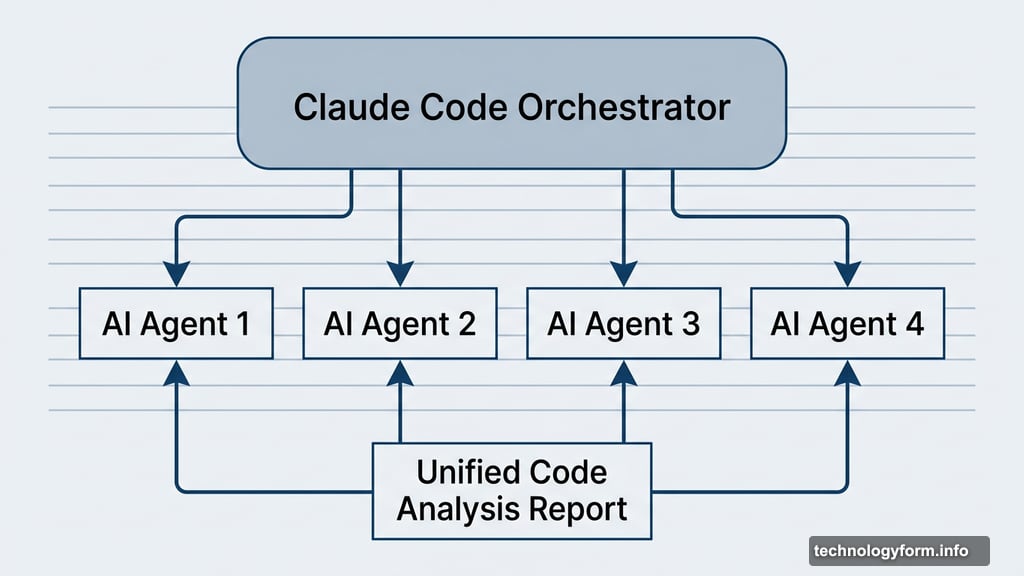
Behind the scenes, multiple AI agents work in parallel. Each agent examines the codebase from a different angle or dimension. Then a final aggregation agent collects all the findings, strips out duplicates, and ranks them by importance.
That parallel structure is why the tool works quickly at scale. But Wu acknowledged it’s also resource-intensive. Code Review costs between $15 and $25 per review on average, with pricing tied to code complexity on a token-based model. For enterprise teams shipping dozens of pull requests daily, that adds up fast.
Engineering leads can also customize additional checks based on their company’s internal best practices, which gives teams more control over what the tool prioritizes. Code Review includes a light security analysis, though Anthropic’s separately launched Claude Code Security handles deeper security scanning for teams that need it.
Built for Uber, Salesforce, and Accenture-Scale Teams
This product targets large enterprise customers specifically. Anthropic named Uber, Salesforce, and Accenture as examples of companies already using Claude Code that now need help managing the sheer volume of pull requests the tool produces.
Developer leads can switch on Code Review as a default setting that applies automatically to every engineer on the team. That means the review process runs without anyone needing to remember to trigger it.
The timing of this launch matters for Anthropic beyond just the product itself. The company filed two lawsuits against the Department of Defense on Monday after the agency designated Anthropic as a supply chain risk. That dispute makes the enterprise business even more critical. Enterprise subscriptions have quadrupled since the start of the year, and Claude Code’s run-rate revenue has surpassed $2.5 billion since launch.
The Real Demand Driving This
Wu didn’t frame Code Review as a product Anthropic dreamed up. She framed it as a response to what enterprise customers were already asking for.
“This is something that’s coming from an insane amount of market pull,” Wu said. “As engineers develop with Claude Code, they’re seeing the friction to creating a new feature decrease, and they’re seeing a much higher demand for code review.”
That’s the interesting tension at the center of this launch. AI tools like Claude Code made it easier to write software. But that ease created a new pressure point downstream in the development process. So the solution is more AI, specifically designed to review the output of the first AI.
Whether that flywheel produces genuinely better software or just more automated noise is what developers will find out in the research preview. But the demand is clearly real, and Anthropic is betting that enterprises will pay a premium to close the gap between AI-generated code and production-ready code.
![Diagram illustrating the multi-agent code review workflow in Claude Code, with parallel AI agents analyzing a codebase and a final aggregation agent ranking findings by severity]