
Encyclopedia Britannica Just Sued OpenAI Over ChatGPT “Memorizing” Its Content
Encyclopedia Britannica and Merriam-Webster didn’t just fire off a strongly worded letter. They went straight to court.
On Friday, March 16, 2026, the two legendary publishers filed a lawsuit against OpenAI, claiming the company used their copyrighted content to train its AI models — and then had the nerve to spit that content back out, nearly word for word, whenever users asked.
This is one of the most direct copyright challenges we’ve seen yet, and the evidence Britannica is presenting makes it hard to look away.

ChatGPT’s “Memorization” Problem
Here’s what makes this lawsuit different from the usual vague copyright complaints. Britannica isn’t just saying OpenAI trained on its content generally. The complaint gets specific.
According to the filing, GPT-4 has effectively “memorized” large portions of Britannica’s text. When someone prompts the model, it can output near-verbatim copies of significant passages on demand. The lawsuit includes side-by-side comparisons showing entire blocks of text that match word for word between ChatGPT responses and Britannica’s original articles.
That’s a bold piece of evidence to put in front of a judge.
Plus, Britannica argues these memorized outputs aren’t just copyright violations — they’re also eating into its business. The complaint accuses OpenAI of “cannibalizing” Britannica’s web traffic by generating responses that directly compete with its content, rather than sending curious readers to Britannica’s website. A traditional search engine would link you to the source. ChatGPT just answers and moves on.
A Pattern Bigger Than One Lawsuit
This isn’t happening in a vacuum. Britannica and Merriam-Webster are joining a growing list of publishers taking AI companies to court.

The New York Times filed a similar lawsuit against OpenAI, also accusing the company of copying massive amounts of its copyrighted content. That case is still ongoing. Meanwhile, Anthropic recently settled a class action over using copyrighted books to train its AI models — that settlement landed at a staggering $1.5 billion paid out to the affected authors.
So there’s now real legal precedent forming around AI companies and copyright. Publishers are watching those outcomes closely.
Why This Case Could Actually Matter
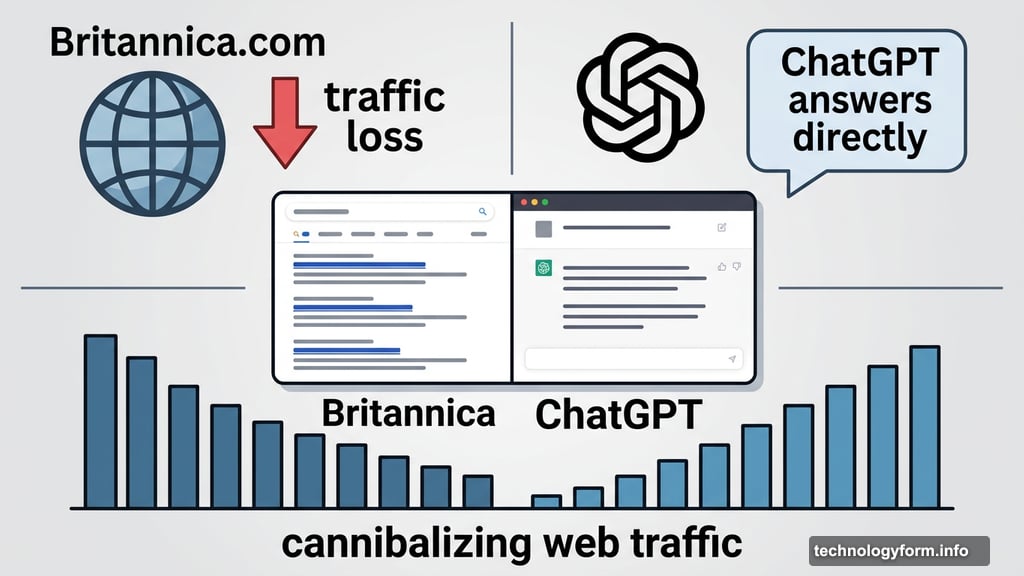
Most AI copyright debates stay pretty abstract. Whose data trained the model? When? How much? It’s hard to prove.
But Britannica’s approach cuts through that fog. If you can show a judge that a chatbot reproduces your specific text on request — complete with matching passages sitting right there in a court filing — the argument becomes a lot more concrete. The memorization angle is clever, and it shifts the conversation from “did you use our content to train?” to “are you distributing our content right now?”
That distinction matters. And it might matter a lot when a judge weighs the evidence.
For anyone who’s ever wondered how AI companies handle the content they train on, this case is worth watching. The outcome won’t just affect OpenAI and Britannica — it could reshape how the entire AI industry thinks about copyright, training data, and what it actually means to “use” someone’s work without permission.





