Reddit Just Sued Perplexity for Stealing Posts. Here’s the Proof
Reddit caught Perplexity red-handed using its content without permission. Now the lawsuit reveals exactly how they proved it.
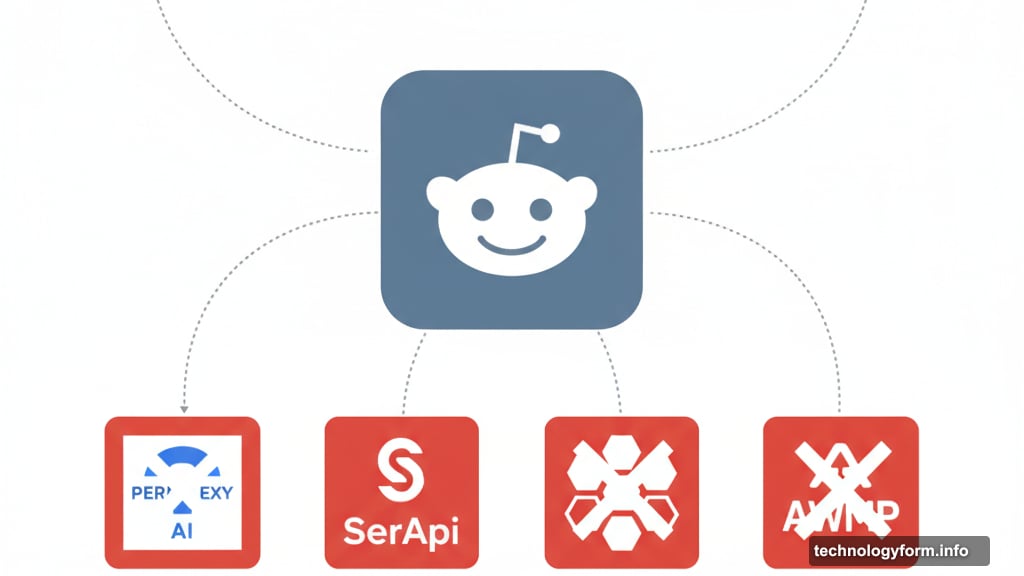
The social platform isn’t just going after Perplexity, though. Three other data scraping companies—SerApi, OxyLabs, and AWMProxy—face the same legal action. All four allegedly scraped Reddit posts from Google search results and used that data without paying licensing fees.
This marks Reddit’s second major AI lawsuit after suing Anthropic for similar violations last year. But this time, Reddit brought receipts that show how companies dodge content licensing requirements.
The Clever Trap That Caught Perplexity
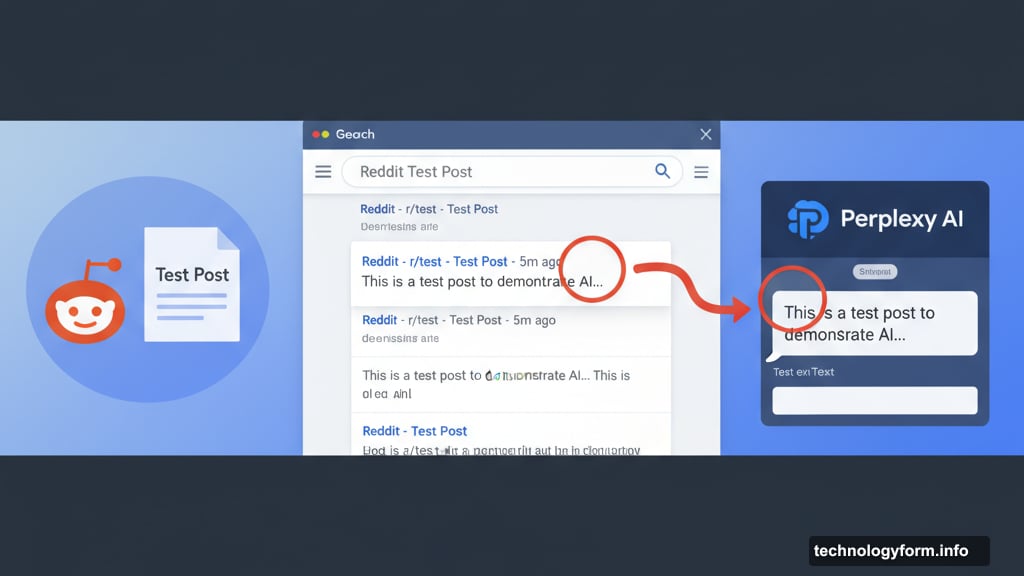
Reddit created a test post designed to expose unauthorized scraping. The post could only be crawled by Google’s search engine and wasn’t accessible anywhere else on the internet.
Within hours, Perplexity’s AI chatbot reproduced the content from that test post. There’s only one way that could happen. Perplexity scraped the content from Google search results and fed it into their answer engine.
So Reddit proved their case with evidence that’s hard to dispute. The test post served as a digital fingerprint proving where Perplexity got its data.
Plus, Reddit had already sent Perplexity a cease-and-desist letter. Perplexity claimed they didn’t use Reddit data. Yet their chatbot kept citing Reddit posts in answers to user queries.
Why Reddit Started Charging for Data Access
Back in 2023, Reddit began charging companies for access to posts and user content. The move targeted AI companies who wanted to train their models on Reddit’s massive collection of conversations.
The platform has since signed licensing deals with major players. Google and OpenAI both pay for legitimate access to Reddit data. That revenue helps Reddit profit from content that users create on its platform.
Reddit even built its own AI answer machine to leverage the knowledge buried in user posts. But unauthorized scraping undermines these business relationships and cuts Reddit out of deals entirely.
The Companies Behind the Data Scraping
SerApi, OxyLabs, and AWMProxy aren’t household names like Perplexity. But they’ve built entire businesses around collecting data from search results and selling it to other companies.
These services make it easy for AI startups to access content without negotiating licensing deals. They act as middlemen who scrape public search results and package that data for sale.
Perplexity’s inclusion in the lawsuit raises bigger questions. The AI company has been caught copying and regurgitating material it hasn’t licensed before. Reports show Perplexity ignored the robots.txt protocol, which websites use to communicate they don’t want their content scraped.
That pattern of behavior suggests Perplexity sees free data access as core to their business model. Now Reddit wants financial damages and a permanent injunction preventing these companies from selling previously scraped Reddit material.
Perplexity’s Defense Sounds Familiar
Perplexity responded with a statement defending “users’ rights to freely and fairly access public knowledge.” They claim their approach remains “principled and responsible.”
However, that argument ignores the difference between reading public content and scraping it at scale to train commercial AI systems. Reddit makes its posts publicly readable. But that doesn’t grant companies permission to harvest that content for profit.
The “public knowledge” defense has become common among AI companies facing copyright lawsuits. Yet courts haven’t consistently accepted this reasoning when companies profit from scraped content.
Meanwhile, Perplexity says they haven’t received the lawsuit yet. That seems odd given the detailed evidence Reddit compiled specifically targeting their service.
Reddit’s Aggressive Data Protection Strategy
This lawsuit fits Reddit’s increasingly aggressive stance on protecting its content. The platform rate-limited unknown bots and web crawlers in 2024.
Then Reddit restricted Internet Archive’s Wayback Machine access in August 2025. That move surprised many users who valued having archived versions of Reddit discussions.

Reddit also adopted the Really Simple Licensing standard, which adds licensing terms to the robots.txt protocol. That creates clearer legal ground for prosecuting unauthorized scraping.
These actions show Reddit treating user-generated content as valuable intellectual property. The company invested in infrastructure to monetize that data through licensing deals rather than letting AI companies take it for free.
The Bigger Battle Over AI Training Data
Reddit’s lawsuit represents a broader conflict over who owns public internet content. AI companies argue they should access public posts to train better models that benefit everyone.
Content platforms counter that training commercial AI systems goes beyond normal public access. They want compensation when their data powers profitable AI services.
Courts will ultimately decide where to draw these lines. But Reddit’s approach—proving scraping with test posts and seeking injunctions—could become a template for other platforms.
For now, companies like Perplexity face a choice. Pay for legitimate data access through licensing deals or fight expensive legal battles over unauthorized scraping.
The days of treating public web content as a free-for-all for AI training appear to be ending. Reddit just made that message very clear.