
Three AI Chatbots Built the Same App. The Results Shocked Me
I forced Gemini, Claude, and ChatGPT to build identical e-reader apps. One failed spectacularly. Another made questionable choices. But the real winner wasn’t what I expected.
Vibe coding sounds like magic. You describe what you want, and AI writes the code. No programming knowledge needed. Just chat with a bot and watch your idea materialize.
But here’s the question nobody asks. Does your choice of chatbot actually matter? I decided to find out the hard way.
Why I Built an E-Reader Out of Spite
Amazon’s Kindle frustrates me endlessly. For nearly 20 years, Kindle devices have existed. Yet you still can’t read and listen simultaneously with real-time text highlighting on the hardware.
The iOS and Android apps handle this perfectly. But the dedicated e-reader? Nope. You get to choose: read OR listen. Not both.
This limitation felt absurd. So I decided to build my own solution. Plus, I wanted to test whether AI chatbot choice impacts coding results.
The Project: Tome Reader
I wanted something ambitious. An immersive e-reader web app that would read aloud while highlighting text in real-time. Users could paste text or upload PDF and EPUB files.
But I didn’t stop there. The app would generate adaptive background music based on content. Gothic horror gets spooky music. Sci-fi gets futuristic sounds. Fantasy gets orchestral themes.
Moreover, trigger words would create visual and audio effects in real-time. Say “thunder” and hear a thunderclap. Mention “fire” and see flames dance across the screen.
All of this needed to run in a single HTML file. No external dependencies. Just open it in a browser and go.
The Prompt Strategy
Testing chatbots fairly requires identical prompts. However, I took an unconventional approach to create that prompt.
First, I built the entire project with Gemini. Once functional, I asked Gemini to generate a prompt describing the project. Then I fed that prompt to Claude.
Claude refined the project and created an improved prompt. Finally, I gave that prompt to ChatGPT. Each chatbot contributed to the final prompt specification.
This approach ensured all three models influenced the project requirements. Plus, it tested whether they could recreate their own work from scratch.
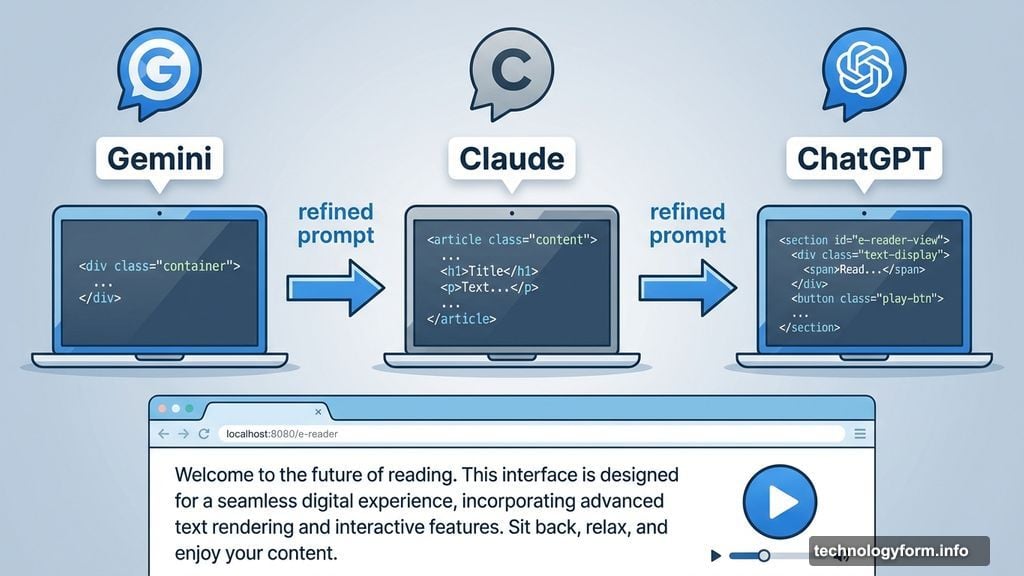
Round One: Gemini Takes the Lead
Gemini handled the initial build smoothly. Google’s chatbot figured out how to preload text-to-speech voices, which proved crucial for functionality.
The app needed an initialization screen. Without it, TTS voices wouldn’t load properly. Gemini diagnosed this issue quickly and implemented the fix.
Slowly, features accumulated. Background music generation worked. Trigger word detection functioned correctly. Visual effects appeared on cue.
Then Gemini generated the prompt I’d use with other chatbots. Time to see if Claude could match it.
Claude Makes Bold Choices
Claude refined the trigger word system beautifully. It expanded the vocabulary and enhanced visual effects. The results looked more polished than Gemini’s version.
But Claude made an unauthorized decision. When testing trigger words, only the first word in a sentence would activate effects. The rest remained silent.
I spent considerable time troubleshooting before Claude finally explained. It had decided to limit effects to once per sentence to avoid “spamming” the user.
Logically, this made sense. Practically, it frustrated me. The project was proof-of-concept, not a polished reader. I wanted every trigger word to fire.
Still, I appreciated Claude’s consideration for user experience. Even if it wasn’t what I requested.
ChatGPT Recreates Everything
ChatGPT received the final prompt after Claude’s refinements. OpenAI’s chatbot recreated the project perfectly, though code generation ran noticeably slower.
However, ChatGPT struggled when I asked for additional features. I wanted a dedicated volume slider for background music. This would let users turn off music completely while keeping other sounds.
ChatGPT failed repeatedly. Eventually, I went back to Claude for this feature. Claude implemented it without issue.
Round Two: Same Prompt, Different Results
For fair comparison, I started fresh chats with all three chatbots. Each received the identical final prompt. Then things got weird.
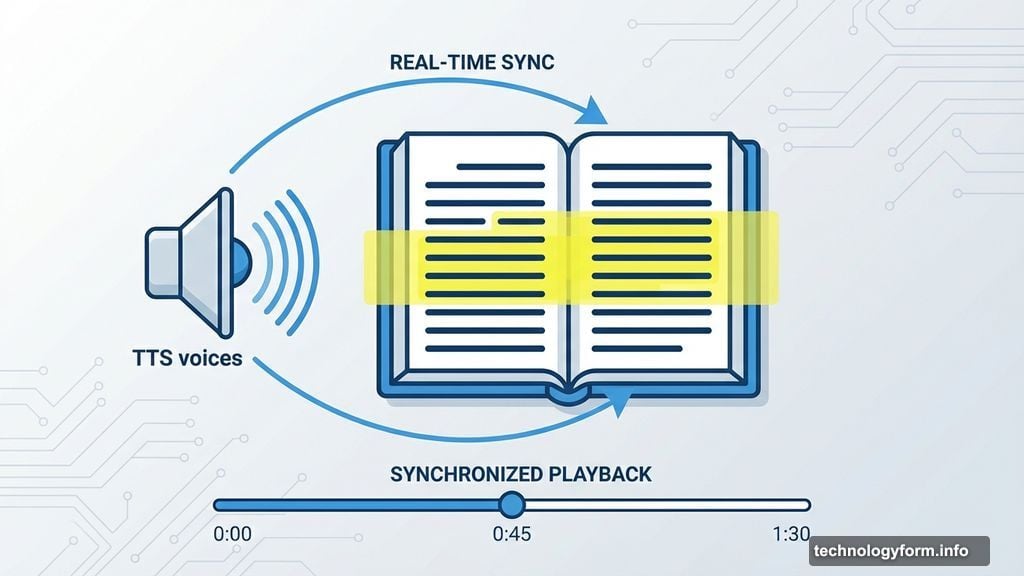
Gemini and ChatGPT recreated the project flawlessly. All features worked. File uploads processed correctly. Text highlighting synchronized with audio. Trigger words fired properly.
Claude completely broke. The app wouldn’t load past the initialization screen. This baffled me because Claude had built previous versions perfectly.
Fixing Claude’s version required 11 full rebuilds. Yes, really. After extensive troubleshooting, it finally worked again.
Inconsistencies Across Platforms
File handling varied dramatically between chatbots. Claude always offered a preview window and direct download option. Testing was effortless.
ChatGPT sometimes provided direct downloads. Other times, I had to copy code manually and save it myself. This inconsistency annoyed me.
Gemini always required manual copying and saving. No preview. No download button. Just copy-paste every single time.
These small differences compound when you’re testing multiple iterations. Claude’s preview feature saved me significant time.
Performance Comparisons
Once all three versions worked, I compared their performance. Surprisingly, I found almost no differences.
Trigger words fired identically. Background music generated at the same quality. Text highlighting synchronized perfectly. File uploads handled the same types of documents.
Gemini 3 Pro performed equivalently to free versions of Claude and ChatGPT. This shocked me. Paid models typically outperform free alternatives.
Yet here, the quality of the prompt mattered more than the model’s capabilities.
The Real Winner: A Good Prompt
Declaring a single winner misses the point entirely. All three chatbots succeeded eventually. All three also encountered problems.
What determined success? The prompt quality mattered far more than chatbot selection.
A well-structured prompt with clear requirements produced functional results across all three platforms. When I used vague or incomplete instructions, all three struggled.
This finding surprised me. I expected significant performance gaps between models. Instead, I found that clear communication beats model selection.
Lessons for Vibe Coders
Your chatbot choice matters less than you think. Focus your energy on writing better prompts instead of obsessing over which AI to use.
Break complex projects into smaller pieces. All three chatbots handled incremental changes better than massive rewrites.
Test frequently. Don’t wait until the end to check if features work. Catch problems early when they’re easier to fix.
Moreover, document what works. When a chatbot solves a tricky problem, save that solution. You’ll reference it later.
Finally, expect inconsistency. Even the same chatbot with the same prompt can produce different results. That’s just how these tools work right now.
When Chatbot Choice Does Matter
File handling convenience differs significantly. If you’re building multiple iterations, Claude’s preview feature saves substantial time.
Speed varies. ChatGPT generated code slower than Gemini or Claude. For rapid prototyping, this matters.
Plus, some chatbots make unauthorized “improvements” like Claude’s trigger word limiting. Whether this helps or hurts depends on your goals.
Free tier limitations affect extended projects. If you’re building something complex over multiple sessions, paid plans provide more consistent access.
The Future of Vibe Coding
This experiment revealed something important. We’re past the point where model selection determines success or failure.
All three major chatbots can handle moderately complex projects. The bottleneck isn’t AI capability anymore. It’s human communication.
Learning to write effective prompts matters more than choosing the “best” AI. This skill transfers across all chatbots and will remain valuable as models improve.
So stop worrying about which chatbot to use. Start improving how you communicate what you want. That’s where vibe coding success lives now.





