DeepSeek Just Fixed AI Training’s Biggest Problem
Large AI models keep getting harder to train. DeepSeek thinks they’ve cracked it.
The Chinese AI lab released a new training method called Manifold-Constrained Hyper-Connections (mHC). Plus, their CEO uploaded the paper himself, signaling this isn’t just research—it’s core to their next product.
The technique solves a problem plaguing massive neural networks: how to scale training without exploding costs or collapsing performance.
Memory Costs Were Killing Large Models
Training huge AI models requires massive compute resources. But memory overhead often creates bigger bottlenecks than raw processing power.
Previous methods improved signal flow through deep networks. However, they didn’t control memory expansion effectively. So as models grew larger, training costs spiraled out of control.
DeepSeek’s approach adds a manifold constraint to limit this expansion. The result? Better memory management without sacrificing training efficiency.
They tested mHC on models with 3 billion, 9 billion, and 27 billion parameters. In fact, all three sizes showed stable performance across training runs. That consistency matters because it proves the method scales reliably.

Building on ByteDance’s 2024 Architecture
DeepSeek didn’t start from scratch. Instead, they enhanced ByteDance’s hyper-connection (HC) architecture from 2024.
ByteDance originally improved ResNet, a foundational deep learning framework. ResNet preserved signal strength across network layers but struggled with efficiency at scale. So ByteDance added hyper-connections to improve signal flow.
But even HC faced memory challenges in larger deployments. DeepSeek solved this by introducing the manifold constraint. This adjustment kept HC’s benefits while controlling resource consumption.
Lead researchers Zhenda Xie, Yixuan Wei, and Huanqi Cao confirmed the system enables stable deep learning without collapse. Moreover, they noted mHC requires minimal infrastructure changes for deployment.
That’s crucial. Many promising research methods fail because real-world implementation proves too complex or expensive.
Liang Wenfeng’s Direct Involvement Signals Product Plans

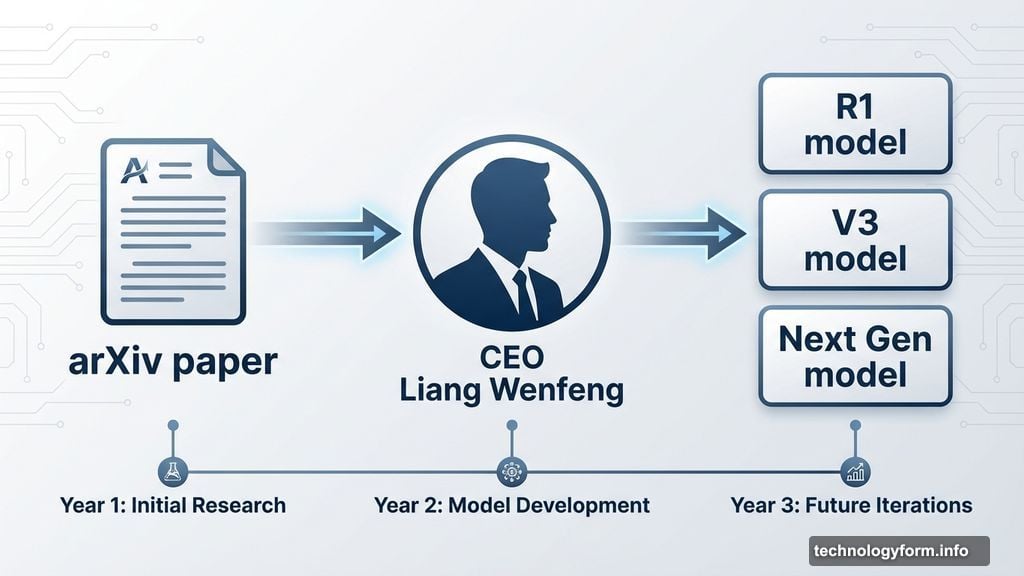
CEO Liang Wenfeng uploaded the paper to arXiv himself. That’s significant because he only personally shares research tied to major product releases.
He previously uploaded papers for DeepSeek’s R1 and V3 models before their launches. Other company researchers publish supporting studies, but Liang handles core technical work directly.
His involvement here suggests mHC will power DeepSeek’s next generation model. Industry watchers expect a release before Spring Festival 2026 based on this pattern.
Florian Brand, a PhD researcher at Trier University, noted DeepSeek’s publication strategy has become predictable. Papers from Liang typically precede model launches by weeks or months.
The R1 model followed exactly this pattern. So technical observers are now watching for product announcements closely.
Why This Actually Matters
Efficient training methods determine which companies can build cutting-edge AI. Right now, only a handful of labs have resources to train frontier models.
DeepSeek’s approach could democratize access to large-scale AI development. If mHC delivers its promised efficiency gains, smaller teams could train competitive models without massive infrastructure investments.
The manifold constraint specifically addresses memory bottlenecks that plague current training runs. By controlling memory expansion, the technique reduces both cost and technical complexity.
This isn’t just academic research. DeepSeek designs methods they plan to deploy in production systems. That practical focus makes their innovations more immediately relevant than purely theoretical work.
DeepSeek Stays Ahead Through Hands-On Leadership
Liang Wenfeng’s direct involvement in technical research distinguishes DeepSeek from competitors. Most AI company CEOs delegate core architecture decisions to research teams.
But Liang continues leading development of the company’s most important systems. This hands-on approach keeps research closely aligned with product strategy.
It also signals confidence in the mHC method. CEOs don’t typically attach their names to speculative research. So his co-authorship suggests DeepSeek considers this architecture production-ready.
The company hasn’t announced specific release dates yet. However, their consistent pattern of research publication followed by product launch has observers expecting news soon.
mHC represents another step in DeepSeek’s strategy of building efficient, scalable AI systems. If the method delivers on its promises, we’ll likely see it powering their next major model release within months.





