OpenAI Admits Prompt Injection Attacks Won’t Ever Stop
OpenAI just confirmed what security experts feared. Their Atlas AI browser faces an unfixable security problem.
The company released a blog post Monday explaining how they’re fighting prompt injection attacks. But here’s the uncomfortable truth buried in the update: these attacks probably can’t be stopped. Ever.
That’s not a small admission. It means AI agents browsing the web on your behalf might always carry risk. And OpenAI knows it.
The Security Flaw That Won’t Die
Prompt injection attacks sound technical. But the concept is simple.
Hackers hide malicious instructions in web pages or emails. When an AI agent reads that content, it follows the hidden commands instead of your instructions. So your helpful AI assistant becomes a security liability.
OpenAI launched Atlas in October 2024. Security researchers immediately exposed the flaws. Someone wrote a few words in Google Docs that completely changed how the browser behaved. Not good.
Other AI browsers face identical problems. Brave published findings showing that Perplexity’s Comet browser has the same vulnerability. Plus, the UK’s National Cyber Security Centre warned in December that these attacks “may never be totally mitigated.”
So every major player in AI browsing admits the same thing. This problem isn’t going away.
OpenAI’s Response: Fight Fire With Fire
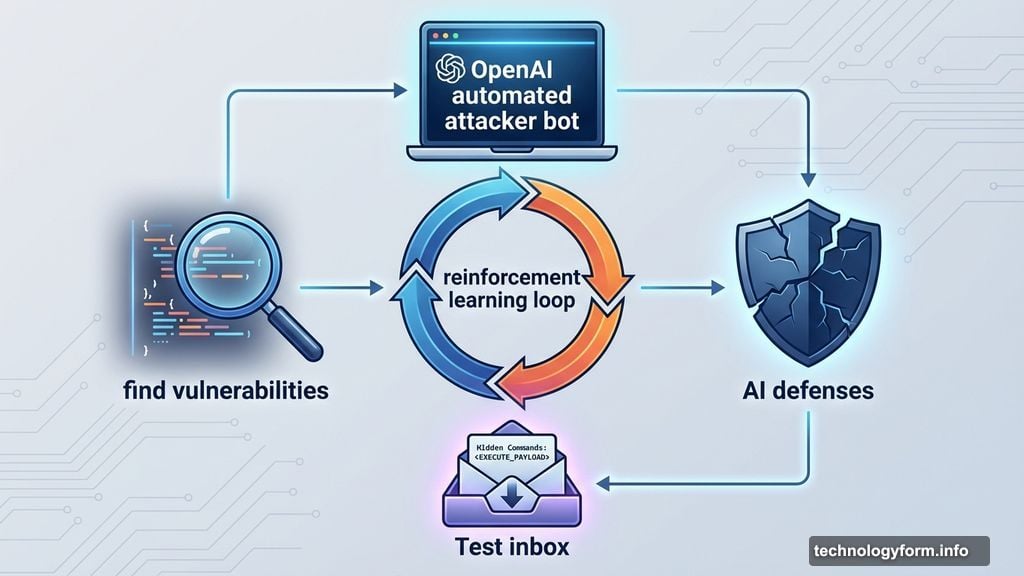
The company’s solution? Build an AI attacker to find vulnerabilities before real hackers do.
OpenAI trained a bot using reinforcement learning to act like a hacker. This automated attacker searches for ways to sneak malicious instructions past AI defenses. Then it tests attacks in simulation, studies how the target AI responds, and refines its approach.

The bot has inside access that real attackers lack. It can see how the target AI thinks and what actions it would take. That means it should find flaws faster than outside hackers.
Does it work? OpenAI shared one demo.
Their automated attacker slipped a malicious email into a test inbox. When the AI agent scanned emails later, it followed hidden instructions and sent a resignation message. The user asked for an out-of-office reply. Instead, the AI quit their job.
After security updates, Atlas detected the attack and warned the user. That’s progress. But it’s also a game of cat and mouse that never ends.
The Risk Trade-Off Nobody Wants to Talk About
Rami McCarthy from cybersecurity firm Wiz puts it bluntly: “Agentic browsers tend to sit in a challenging part of that space: moderate autonomy combined with very high access.”
Translation? These browsers have access to your email, payment info, and sensitive data. That access makes them powerful. But it also makes them dangerous when attacks succeed.
OpenAI recommends users take precautions. Get confirmation before the AI sends messages or makes payments. Give specific instructions instead of broad latitude. Don’t tell Atlas to “take whatever action is needed” with your inbox.
Those safeguards reduce risk. But they also limit what makes AI agents useful in the first place. You either accept some risk or constrain what the AI can do.
McCarthy questions whether the trade-off makes sense yet. “For most everyday use cases, agentic browsers don’t yet deliver enough value to justify their current risk profile,” he told TechCrunch.
That’s the real issue. The technology moves fast. Security doesn’t keep pace.
What This Means For You
Should you use AI browsers right now? That depends on your risk tolerance.
These tools offer convenience. They can handle tasks faster than you would manually. But they also create new attack surfaces that didn’t exist before.
If you do use Atlas or similar AI browsers, follow OpenAI’s advice. Review actions before the AI executes them. Limit access to sensitive accounts. Give narrow, specific instructions rather than open-ended goals.
And remember that no defense is perfect. OpenAI’s updates help. But the company admits this is “a long-term AI security challenge” that requires “continuously strengthened defenses.”
Translation: the attacks will keep coming. Defenses will keep improving. But the gap between them probably won’t close completely.
The Bigger Picture
This isn’t just about one browser or one company. Every AI agent that interacts with the open web faces similar challenges.
Google, Anthropic, and others are building their own defenses. They use layered security and continuous testing. But they’re all fighting the same uphill battle.
The UK government told cyber professionals to focus on reducing risk, not eliminating it. That’s pragmatic advice. But it’s also sobering.
We’re building AI agents to handle sensitive tasks. We’re giving them access to our data and systems. And we’re doing it knowing that perfect security isn’t possible.
Maybe that’s fine. Humans make security mistakes too. But at least we can learn to spot phishing emails and suspicious links. AI agents are still learning.
For now, the safest approach is caution. Use AI browsers for low-risk tasks. Keep them away from critical systems. And stay informed as the security landscape evolves.
Because one thing is certain: prompt injection attacks aren’t disappearing anytime soon.