
Wikipedia Begs AI Companies to Stop Freeloading
Wikipedia’s message to AI developers is crystal clear. Stop scraping our content. Start paying for it.
The Wikimedia Foundation dropped this appeal Monday in what reads less like a request and more like a plea for survival. Why? Because AI bots are hammering their servers while actual human visitors steadily decline.
Traffic Numbers Tell a Brutal Story
Here’s what Wikipedia discovered after updating its bot-detection systems. Those massive traffic spikes in May and June? Not real people seeking knowledge. AI bots disguising themselves as humans to scrape content.
Meanwhile, actual human page views dropped 8% year-over-year. That’s the real crisis. Fewer humans visiting means fewer volunteer editors contributing. Plus, fewer individual donors supporting the nonprofit.
So Wikipedia built a paid API called Wikimedia Enterprise specifically for AI companies. The platform lets developers access content at scale without crushing Wikipedia’s servers. Plus, the revenue supports their nonprofit mission.
Attribution Matters More Than Money
Wikipedia’s bigger concern isn’t just payment. It’s attribution.

The foundation wants AI systems to credit the human contributors who wrote that content. Otherwise, generative AI just becomes a knowledge parasite. It consumes free content created by volunteers, then serves it back to users without acknowledging the source.
This creates a vicious cycle. Users get answers from ChatGPT or Claude instead of visiting Wikipedia. So volunteer contributors don’t see their work reaching people. That kills motivation to keep editing and improving articles.
Indeed, Wikipedia’s entire model depends on passionate volunteers maintaining accuracy. Break that incentive loop and the whole system collapses.
AI Strategy Draws a Line
Earlier this year, Wikipedia released its AI strategy for editors. The approach is pragmatic, not hostile.
AI tools can help editors with tedious workflows. Translation automation speeds up making content available in multiple languages. Other tools assist human editors rather than replacing them.
But that’s using AI to strengthen Wikipedia. It’s completely different from AI companies strip-mining Wikipedia’s content without contributing anything back.
The Polite Threat
What makes Monday’s blog post interesting is what it doesn’t say. No threats of legal action. No promises to block scrapers. Just a calm explanation of the right way forward.
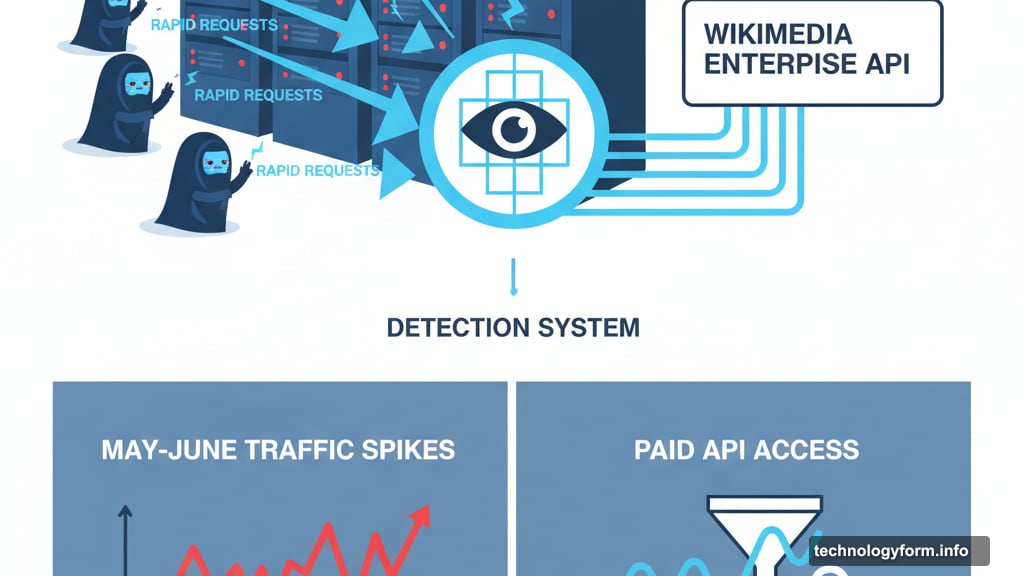
Yet the subtext is clear. Wikipedia now knows which bots are scraping. They upgraded detection specifically to catch AI companies pretending to be human users. So future enforcement seems inevitable if voluntary compliance fails.
For now, Wikipedia is betting on moral suasion. Use our paid API. Attribute our contributors. Support the nonprofit mission that makes this knowledge available.
Your Encyclopedia Needs Help
Here’s the uncomfortable truth. Wikipedia pioneered free, reliable knowledge on the internet. Millions of volunteers built something extraordinary. Now AI companies are turning that gift against them.
Every unanswered question that ChatGPT handles is one less Wikipedia visit. Every response that doesn’t cite sources is one more blow to volunteer motivation. The trend is unsustainable.
AI companies have three options. Pay for the API. Credit their sources properly. Or watch Wikipedia slowly wither from lack of traffic and support.
Most won’t care until Wikipedia actually degrades. Then they’ll complain their AI models lost accuracy because Wikipedia articles got worse. By that point, the damage is done.
The encyclopedia that educated the internet for free deserves better than being quietly strip-mined to death.





